 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Object-level Pre-training with Spatial Noise Curriculum Learning
Paper and Code



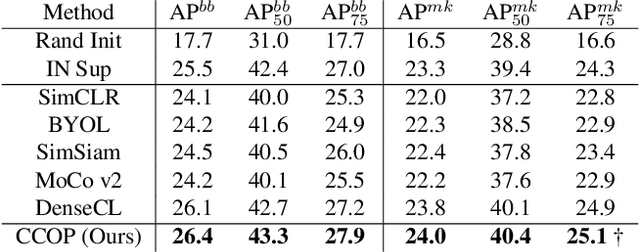
The goal of contrastive learning based pre-training is to leverage large quantities of unlabeled data to produce a model that can be readily adapted downstream. Current approaches revolve around solving an image discrimination task: given an anchor image, an augmented counterpart of that image, and some other images, the model must produce representations such that the distance between the anchor and its counterpart is small, and the distances between the anchor and the other images are large. There are two significant problems with this approach: (i) by contrasting representations at the image-level, it is hard to generate detailed object-sensitive features that are beneficial to downstream object-level tasks such as instance segmentation; (ii) the augmentation strategy of producing an augmented counterpart is fixed, making learning less effective at the later stages of pre-training. In this work, we introduce Curricular Contrastive Object-level Pre-training (CCOP) to tackle these problems: (i) we use selective search to find rough object regions and use them to build an inter-image object-level contrastive loss and an intra-image object-level discrimination loss into our pre-training objective; (ii) we present a curriculum learning mechanism that adaptively augments the generated regions, which allows the model to consistently acquire a useful learning signal, even in the later stages of pre-training. Our experiments show that our approach improves on the MoCo v2 baseline by a large margin on multiple object-level tasks when pre-training on multi-object scene image datasets. Code is available at https://github.com/ChenhongyiYang/CCOP.