 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Multi-Modal Clustering
Paper and Code
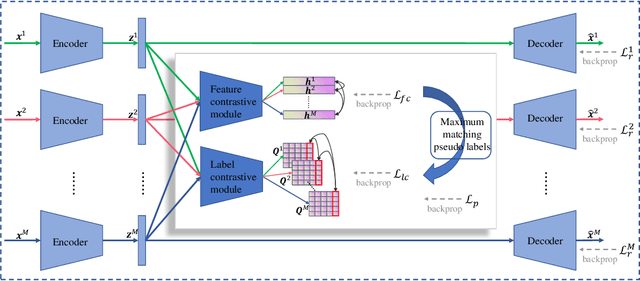
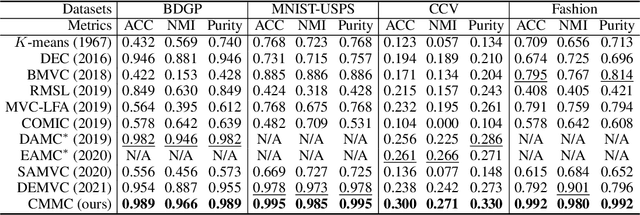
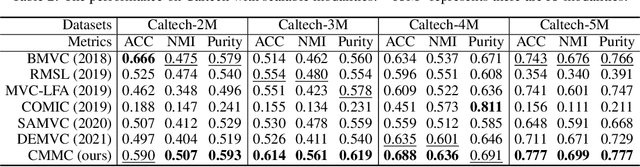
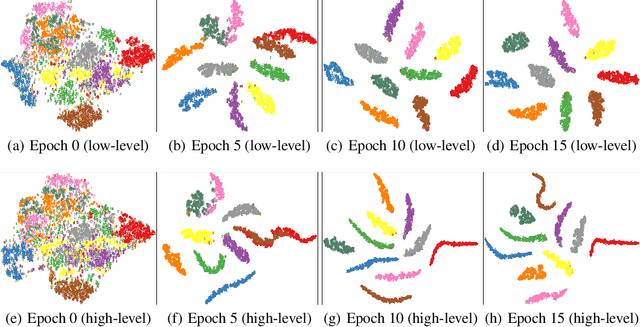
Multi-modal clustering, which explores complementary information from multiple modalities or views, has attracted people's increasing attentions. However, existing works rarely focus on extracting high-level semantic information of multiple modalities for clustering. In this paper, we propose Contrastive Multi-Modal Clustering (CMMC) which can mine high-level semantic information via contrastive learning. Concretely, our framework consists of three parts. (1) Multiple autoencoders are optimized to maintain each modality's diversity to learn complementary information. (2) A feature contrastive module is proposed to learn common high-level semantic features from different modalities. (3) A label contrastive module aims to learn consistent cluster assignments for all modalities. By the proposed multi-modal contrastive learning, the mutual information of high-level features is maximized, while the diversity of the low-level latent features is maintained. In addition, to utilize the learned high-level semantic features, we further generate pseudo labels by solving a maximum matching problem to fine-tune the cluster assignments. Extensive experiments demonstrate that CMMC has good scalability and outperforms state-of-the-art multi-modal clustering methods.