 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrasting Intra-Modal and Ranking Cross-Modal Hard Negatives to Enhance Visio-Linguistic Fine-grained Understanding
Paper and Code
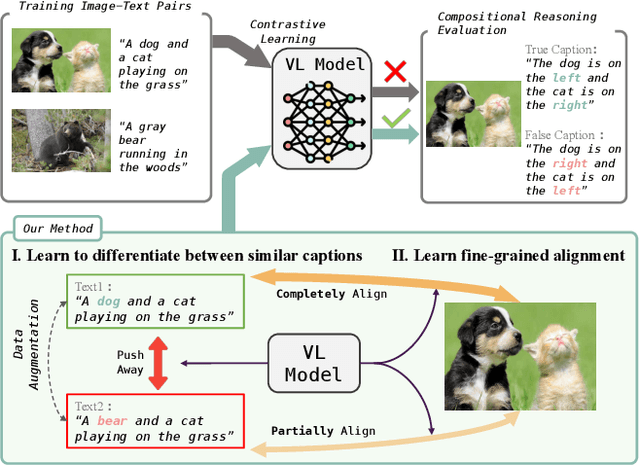
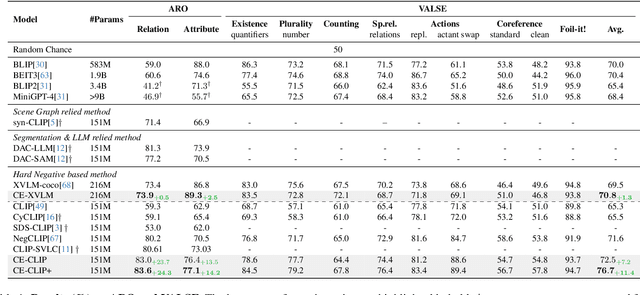
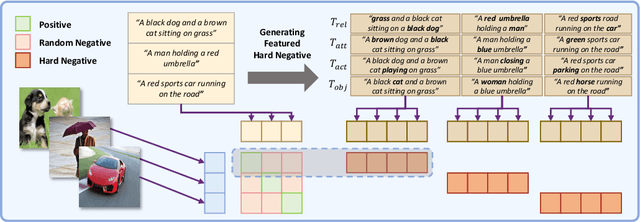
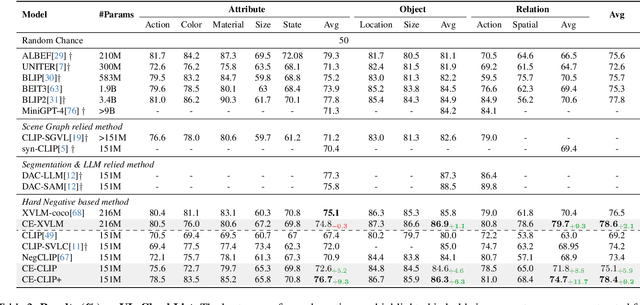
Current Vision and Language Models (VLMs) demonstrate strong performance across various vision-language tasks, yet they struggle with fine-grained understanding. This issue stems from weak image-caption alignment in pretraining datasets and a simplified contrastive objective that fails to distinguish nuanced grounding elements such as relations, actions, and attributes. As a result, the models tend to learn bag-of-words representations. To mitigate these challenges, we introduce an intra-modal contrastive loss and a unique cross-modal rank loss with an adaptive threshold that serves as curriculum learning, utilizing our automatically generated hard negatives to augment the model's capacity. Our strategy, which does not necessitate additional annotations or parameters, can be incorporated into any VLM trained with an image-text contrastive loss. Upon application to CLIP, our method leads to significant improvements on four fine-grained benchmarks, and it also enhances the performance of X-VLM, which is the state-of-art moodel on fine-grained reasoning.