 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContraSolver: Self-Alignment of Language Models by Resolving Internal Preference Contradictions
Paper and Code

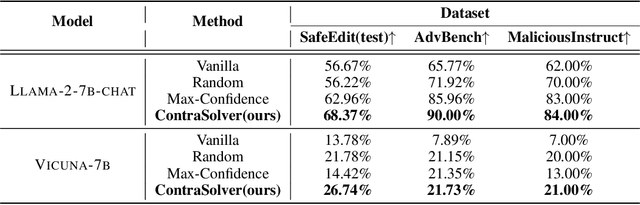


While substantial advancements have been made in developing large language models (LLMs), achieving control over their behavior can be difficult. Direct preference optimization (DPO) assumes the existence of a latent reward function to evaluate the responses of LLMs. This assumption indicates a strict preference ordering of different responses to the same input. However, there always exist contradictions of preference in LLMs according to our experimental observations. In this paper, we construct a graph structure of the preference relationship among different responses with self-annotation to find contradictions in the preference order. We propose ContraSolver, an algorithm that traverses all edges on the preference graph to identify those that might cause contradictions. ContraSolver initializes the graph with a maximum spanning tree and identifies contradictory edges, prioritizing the resolution of low-confidence preferences while preserving high-confidence ones. Experimental results on four different generation tasks show that the performance of different LLMs can be largely improved through our completely unsupervised self-alignment. Furthermore, by analyzing the preference graphs of LLMs with and without self-alignment by ContraSolver, we quantify the reduction in contradictions, suggesting that resolving preference contradictions is crucial for achieving better alignment performance.