 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous ErrP detections during multimodal human-robot interaction
Paper and Code
Jul 25, 2022
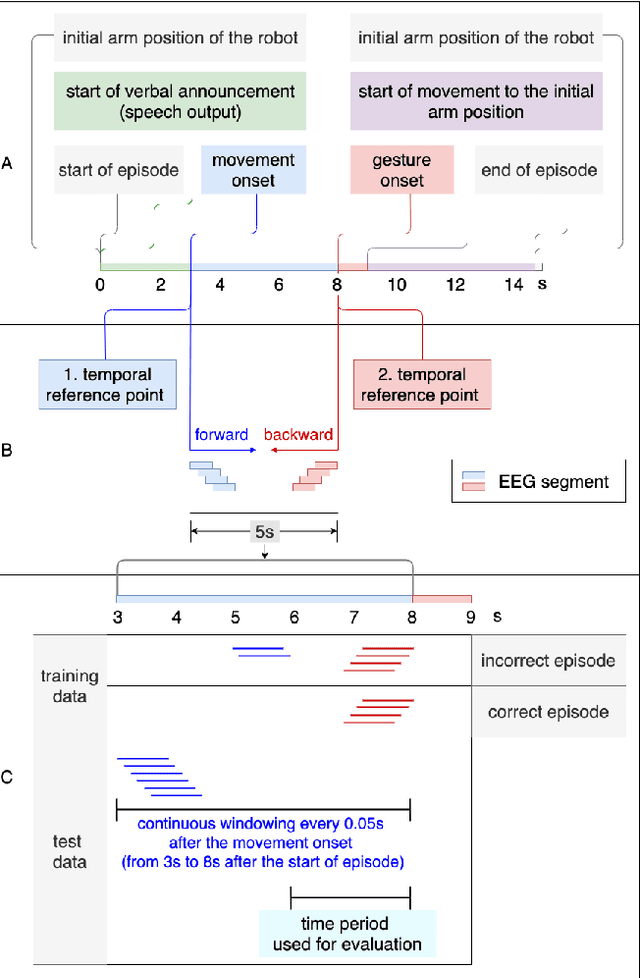
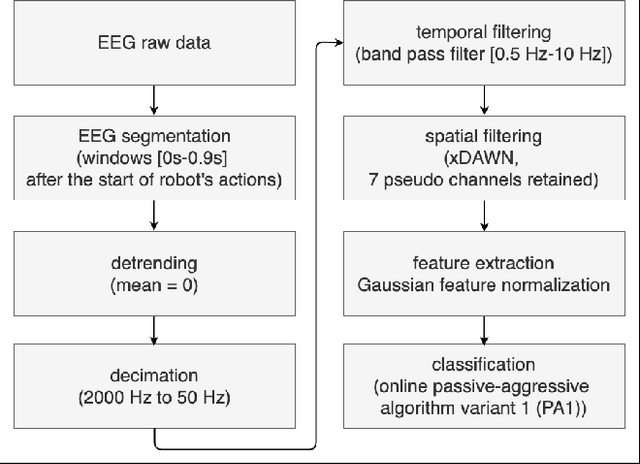
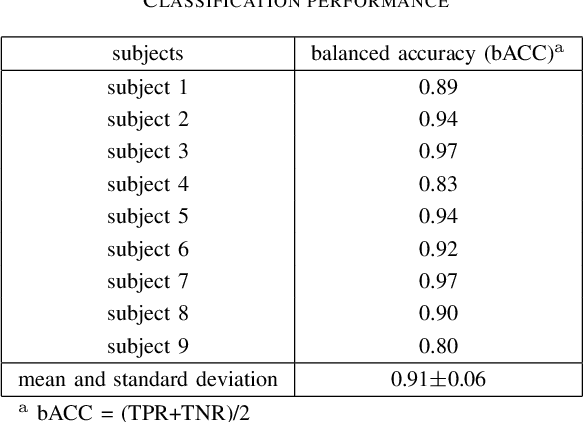
Human-in-the-loop approaches are of great importance for robot applications. In the presented study, we implemented a multimodal human-robot interaction (HRI) scenario, in which a simulated robot communicates with its human partner through speech and gestures. The robot announces its intention verbally and selects the appropriate action using pointing gestures. The human partner, in turn, evaluates whether the robot's verbal announcement (intention) matches the action (pointing gesture) chosen by the robot. For cases where the verbal announcement of the robot does not match the corresponding action choice of the robot, we expect error-related potentials (ErrPs) in the human electroencephalogram (EEG). These intrinsic evaluations of robot actions by humans, evident in the EEG, were recorded in real time, continuously segmented online and classified asynchronously. For feature selection, we propose an approach that allows the combinations of forward and backward sliding windows to train a classifier. We achieved an average classification performance of 91% across 9 subjects. As expected, we also observed a relatively high variability between the subjects. In the future, the proposed feature selection approach will be extended to allow for customization of feature selection. To this end, the best combinations of forward and backward sliding windows will be automatically selected to account for inter-subject variability in classification performance. In addition, we plan to use the intrinsic human error evaluation evident in the error case by the ErrP in interactive reinforcement learning to improve multimodal human-robot interaction.