 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Control with Deep Reinforcement Learning for Autonomous Vessels
Paper and Code
Jun 27, 2021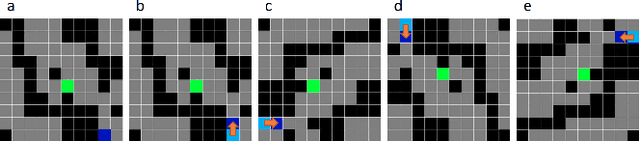
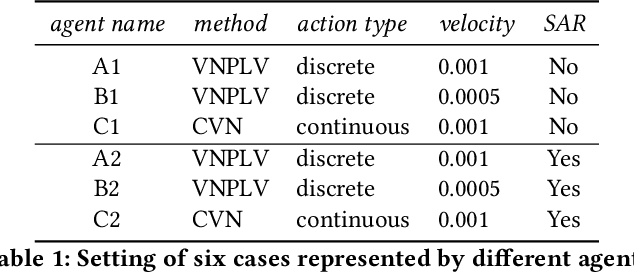
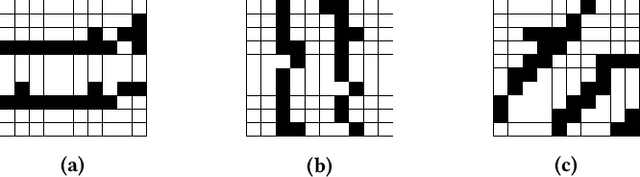
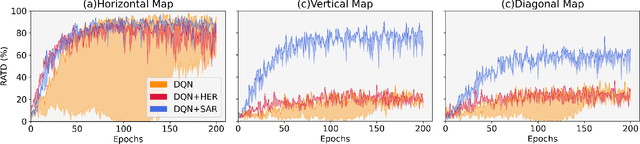
Maritime autonomous transportation has played a crucial role in the globalization of the world economy. Deep Reinforcement Learning (DRL) has been applied to automatic path planning to simulate vessel collision avoidance situations in open seas. End-to-end approaches that learn complex mappings directly from the input have poor generalization to reach the targets in different environments. In this work, we present a new strategy called state-action rotation to improve agent's performance in unseen situations by rotating the obtained experience (state-action-state) and preserving them in the replay buffer. We designed our model based on Deep Deterministic Policy Gradient, local view maker, and planner. Our agent uses two deep Convolutional Neural Networks to estimate the policy and action-value functions. The proposed model was exhaustively trained and tested in maritime scenarios with real maps from cities such as Montreal and Halifax. Experimental results show that the state-action rotation on top of the CVN consistently improves the rate of arrival to a destination (RATD) by up 11.96% with respect to the Vessel Navigator with Planner and Local View (VNPLV), as well as it achieves superior performance in unseen mappings by up 30.82%. Our proposed approach exhibits advantages in terms of robustness when tested in a new environment, supporting the idea that generalization can be achieved by using state-action rotation.