 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Guided Spatio-Temporal Video Grounding
Paper and Code
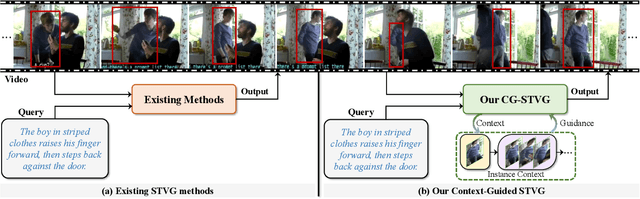

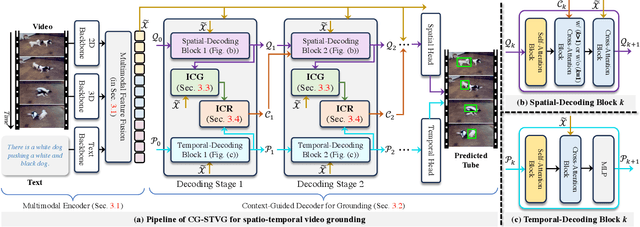

Spatio-temporal video grounding (or STVG) task aims at locating a spatio-temporal tube for a specific instance given a text query. Despite advancements, current methods easily suffer the distractors or heavy object appearance variations in videos due to insufficient object information from the text, leading to degradation. Addressing this, we propose a novel framework, context-guided STVG (CG-STVG), which mines discriminative instance context for object in videos and applies it as a supplementary guidance for target localization. The key of CG-STVG lies in two specially designed modules, including instance context generation (ICG), which focuses on discovering visual context information (in both appearance and motion) of the instance, and instance context refinement (ICR), which aims to improve the instance context from ICG by eliminating irrelevant or even harmful information from the context. During grounding, ICG, together with ICR, are deployed at each decoding stage of a Transformer architecture for instance context learning. Particularly, instance context learned from one decoding stage is fed to the next stage, and leveraged as a guidance containing rich and discriminative object feature to enhance the target-awareness in decoding feature, which conversely benefits generating better new instance context for improving localization finally. Compared to existing methods, CG-STVG enjoys object information in text query and guidance from mined instance visual context for more accurate target localization. In our experiments on three benchmarks, including HCSTVG-v1/-v2 and VidSTG, CG-STVG sets new state-of-the-arts in m_tIoU and m_vIoU on all of them, showing its efficacy. The code will be released at https://github.com/HengLan/CGSTVG.