 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Semantic Inpainting
Paper and Code
Dec 21, 2017
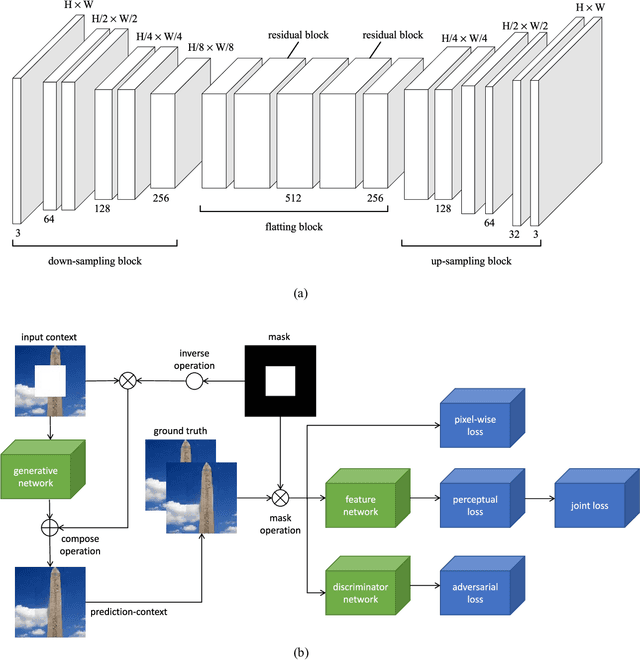
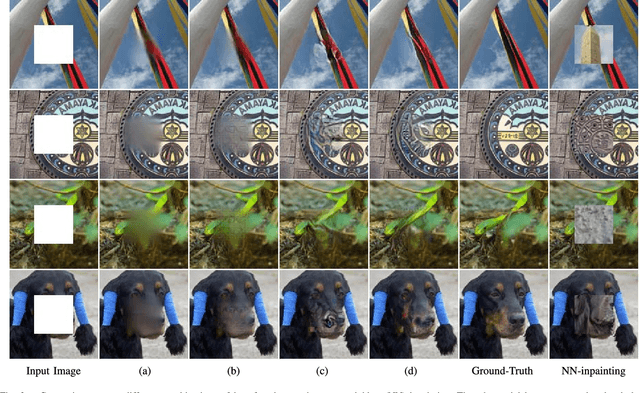

Recently image inpainting has witnessed rapid progress due to generative adversarial networks (GAN) that are able to synthesize realistic contents. However, most existing GAN-based methods for semantic inpainting apply an auto-encoder architecture with a fully connected layer, which cannot accurately maintain spatial information. In addition, the discriminator in existing GANs struggle to understand high-level semantics within the image context and yield semantically consistent content. Existing evaluation criteria are biased towards blurry results and cannot well characterize edge preservation and visual authenticity in the inpainting results. In this paper, we propose an improved generative adversarial network to overcome the aforementioned limitations. Our proposed GAN-based framework consists of a fully convolutional design for the generator which helps to better preserve spatial structures and a joint loss function with a revised perceptual loss to capture high-level semantics in the context. Furthermore, we also introduce two novel measures to better assess the quality of image inpainting results. Experimental results demonstrate that our method outperforms the state of the art under a wide range of criteria.