 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing Image-Text Pair Dataset from Books
Paper and Code
Oct 03, 2023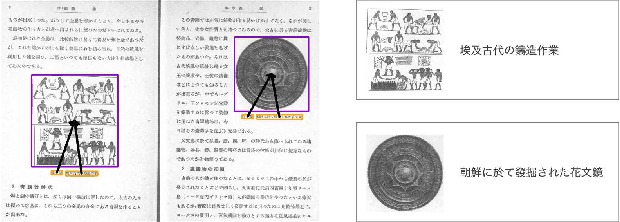

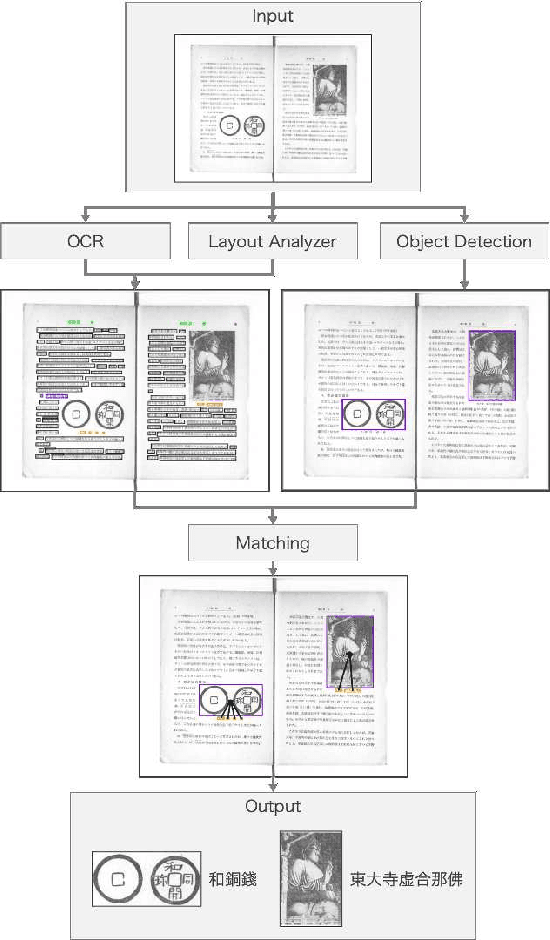

Digital archiving is becoming widespread owing to its effectiveness in protecting valuable books and providing knowledge to many people electronically. In this paper, we propose a novel approach to leverage digital archives for machine learning. If we can fully utilize such digitized data, machine learning has the potential to uncover unknown insights and ultimately acquire knowledge autonomously, just like humans read books. As a first step, we design a dataset construction pipeline comprising an optical character reader (OCR), an object detector, and a layout analyzer for the autonomous extraction of image-text pairs. In our experiments, we apply our pipeline on old photo books to construct an image-text pair dataset, showing its effectiveness in image-text retrieval and insight extraction.