 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Multilabel Ranking through Univariate Losses
Paper and Code
Jun 27, 2012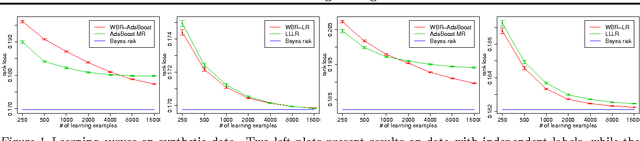
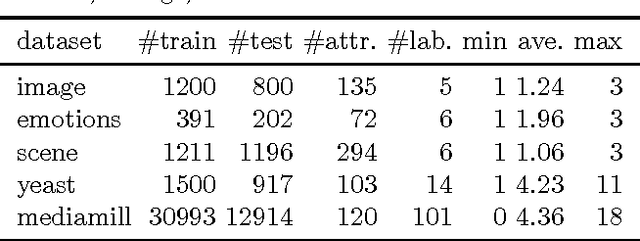
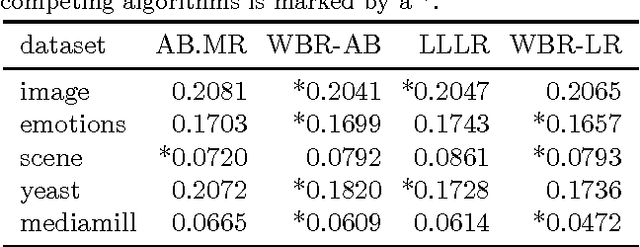
We consider the problem of rank loss minimization in the setting of multilabel classification, which is usually tackled by means of convex surrogate losses defined on pairs of labels. Very recently, this approach was put into question by a negative result showing that commonly used pairwise surrogate losses, such as exponential and logistic losses, are inconsistent. In this paper, we show a positive result which is arguably surprising in light of the previous one: the simpler univariate variants of exponential and logistic surrogates (i.e., defined on single labels) are consistent for rank loss minimization. Instead of directly proving convergence, we give a much stronger result by deriving regret bounds and convergence rates. The proposed losses suggest efficient and scalable algorithms, which are tested experimentally.