 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConnected Superlevel Set in (Deep) Reinforcement Learning and its Application to Minimax Theorems
Paper and Code
Mar 23, 2023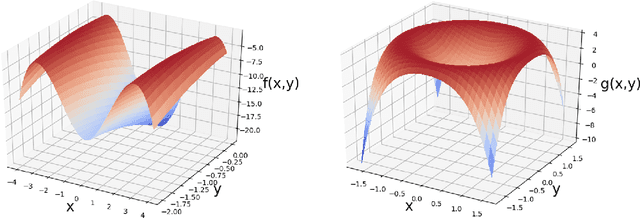
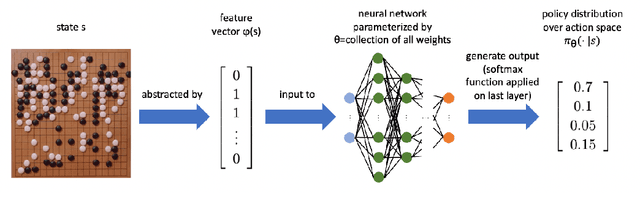
The aim of this paper is to improve the understanding of the optimization landscape for policy optimization problems in reinforcement learning. Specifically, we show that the superlevel set of the objective function with respect to the policy parameter is always a connected set both in the tabular setting and under policies represented by a class of neural networks. In addition, we show that the optimization objective as a function of the policy parameter and reward satisfies a stronger "equiconnectedness" property. To our best knowledge, these are novel and previously unknown discoveries. We present an application of the connectedness of these superlevel sets to the derivation of minimax theorems for robust reinforcement learning. We show that any minimax optimization program which is convex on one side and is equiconnected on the other side observes the minimax equality (i.e. has a Nash equilibrium). We find that this exact structure is exhibited by an interesting robust reinforcement learning problem under an adversarial reward attack, and the validity of its minimax equality immediately follows. This is the first time such a result is established in the literature.