 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational-Statistical Gaps in Reinforcement Learning
Paper and Code
Feb 11, 2022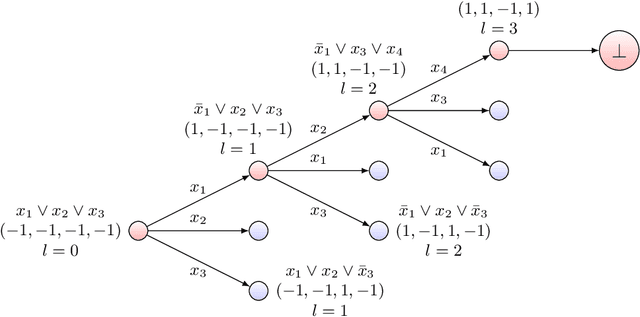
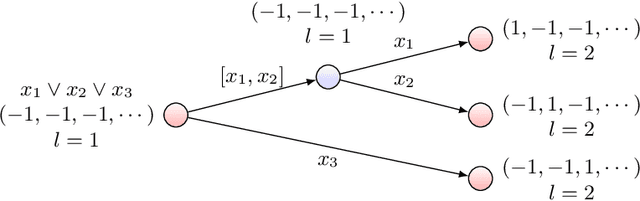
Reinforcement learning with function approximation has recently achieved tremendous results in applications with large state spaces. This empirical success has motivated a growing body of theoretical work proposing necessary and sufficient conditions under which efficient reinforcement learning is possible. From this line of work, a remarkably simple minimal sufficient condition has emerged for sample efficient reinforcement learning: MDPs with optimal value function $V^*$ and $Q^*$ linear in some known low-dimensional features. In this setting, recent works have designed sample efficient algorithms which require a number of samples polynomial in the feature dimension and independent of the size of state space. They however leave finding computationally efficient algorithms as future work and this is considered a major open problem in the community. In this work, we make progress on this open problem by presenting the first computational lower bound for RL with linear function approximation: unless NP=RP, no randomized polynomial time algorithm exists for deterministic transition MDPs with a constant number of actions and linear optimal value functions. To prove this, we show a reduction from Unique-Sat, where we convert a CNF formula into an MDP with deterministic transitions, constant number of actions and low dimensional linear optimal value functions. This result also exhibits the first computational-statistical gap in reinforcement learning with linear function approximation, as the underlying statistical problem is information-theoretically solvable with a polynomial number of queries, but no computationally efficient algorithm exists unless NP=RP. Finally, we also prove a quasi-polynomial time lower bound under the Randomized Exponential Time Hypothesis.