 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing Large Language Models by Streamlining the Unimportant Layer
Paper and Code
Mar 31, 2024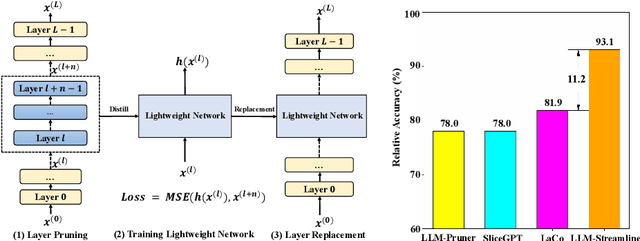


Large language models (LLM) have been extensively applied in various natural language tasks and domains, but their applicability is constrained by the large number of parameters of the models. Consequently, there is an increasing emphasis on compact models that exhibit high performance. In this study, we observe that different layers in LLM have varying degrees of perturbation on the hidden states, which allows us to identify less important layers. Based on this phenomenon, we propose LLM-Streamline, which consists of two parts: layer pruning, where we remove a set of consecutive layers with the lowest importance in the model according to the target sparsity; and layer replacement, where we train a lightweight model to substitute the pruned layers, thereby mitigating the performance degradation caused by pruning. In our experiments, we utilize structures such as a multi-layer perceptron (MLP) and a transformer layer as lightweight models and ultimately demonstrate that a single MLP can effectively fit the pruned layers. Comprehensive experiments show that our proposed method, LLM-Streamline, outperforms previous state-of-the-art (SOTA) model pruning methods.