 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-efficient Decentralized Local SGD over Undirected Networks
Paper and Code
Nov 06, 2020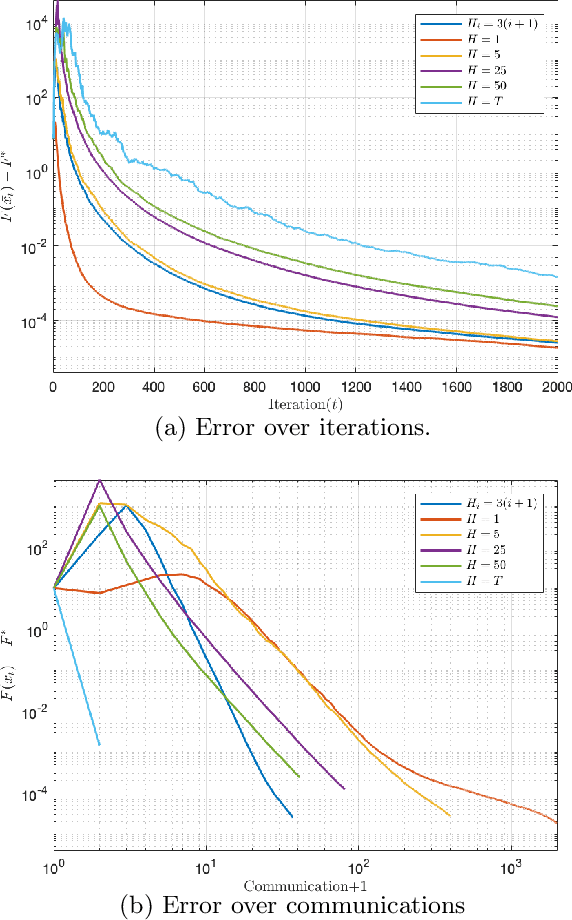
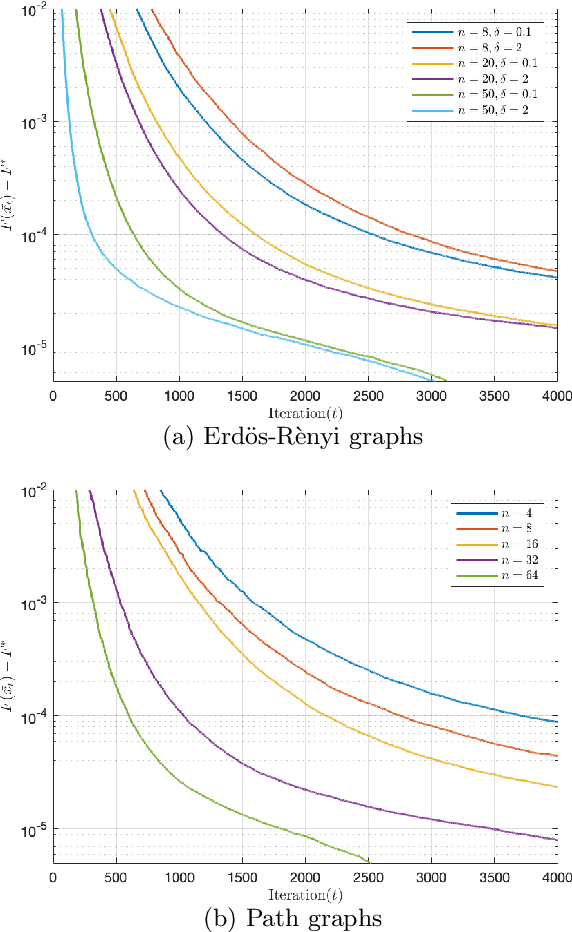
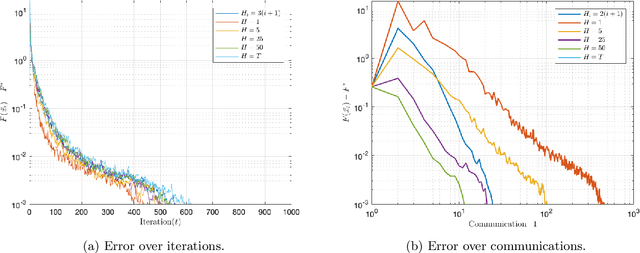
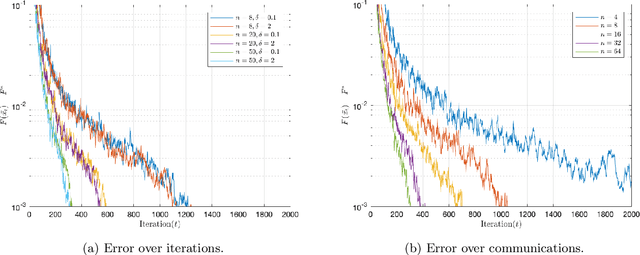
We consider the distributed learning problem where a network of $n$ agents seeks to minimize a global function $F$. Agents have access to $F$ through noisy gradients, and they can locally communicate with their neighbors a network. We study the Decentralized Local SDG method, where agents perform a number of local gradient steps and occasionally exchange information with their neighbors. Previous algorithmic analysis efforts have focused on the specific network topology (star topology) where a leader node aggregates all agents' information. We generalize that setting to an arbitrary network by analyzing the trade-off between the number of communication rounds and the computational effort of each agent. We bound the expected optimality gap in terms of the number of iterates $T$, the number of workers $n$, and the spectral gap of the underlying network. Our main results show that by using only $R=\Omega(n)$ communication rounds, one can achieve an error that scales as $O({1}/{nT})$, where the number of communication rounds is independent of $T$ and only depends on the number of agents. Finally, we provide numerical evidence of our theoretical results through experiments on real and synthetic data.