 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Learning and Personalization in Multi-Agent Stochastic Linear Bandits
Paper and Code
Jun 15, 2021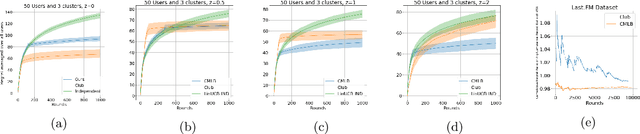
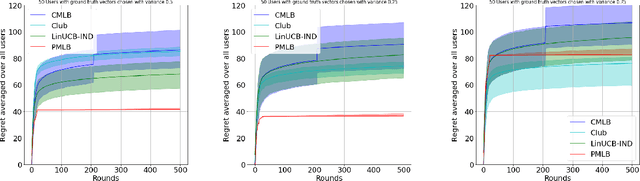
We consider the problem of minimizing regret in an $N$ agent heterogeneous stochastic linear bandits framework, where the agents (users) are similar but not all identical. We model user heterogeneity using two popularly used ideas in practice; (i) A clustering framework where users are partitioned into groups with users in the same group being identical to each other, but different across groups, and (ii) a personalization framework where no two users are necessarily identical, but a user's parameters are close to that of the population average. In the clustered users' setup, we propose a novel algorithm, based on successive refinement of cluster identities and regret minimization. We show that, for any agent, the regret scales as $\mathcal{O}(\sqrt{T/N})$, if the agent is in a `well separated' cluster, or scales as $\mathcal{O}(T^{\frac{1}{2} + \varepsilon}/(N)^{\frac{1}{2} -\varepsilon})$ if its cluster is not well separated, where $\varepsilon$ is positive and arbitrarily close to $0$. Our algorithm is adaptive to the cluster separation, and is parameter free -- it does not need to know the number of clusters, separation and cluster size, yet the regret guarantee adapts to the inherent complexity. In the personalization framework, we introduce a natural algorithm where, the personal bandit instances are initialized with the estimates of the global average model. We show that, an agent $i$ whose parameter deviates from the population average by $\epsilon_i$, attains a regret scaling of $\widetilde{O}(\epsilon_i\sqrt{T})$. This demonstrates that if the user representations are close (small $\epsilon_i)$, the resulting regret is low, and vice-versa. The results are empirically validated and we observe superior performance of our adaptive algorithms over non-adaptive baselines.