 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCODER: Knowledge infused cross-lingual medical term embedding for term normalization
Paper and Code
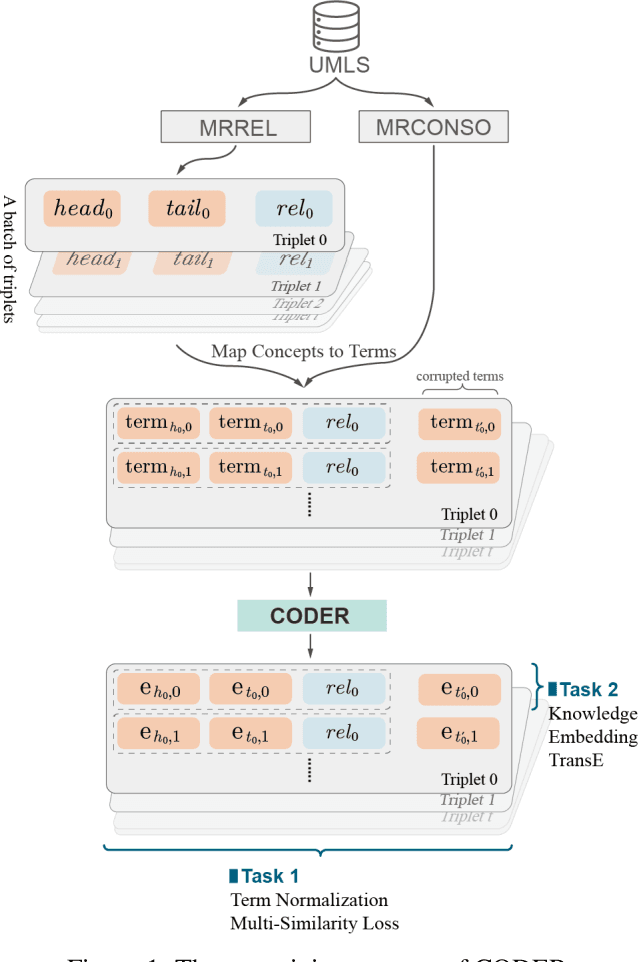

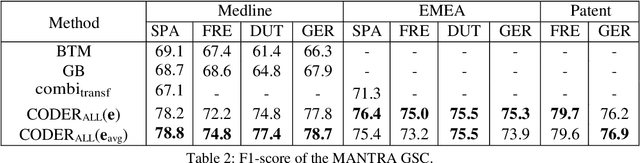
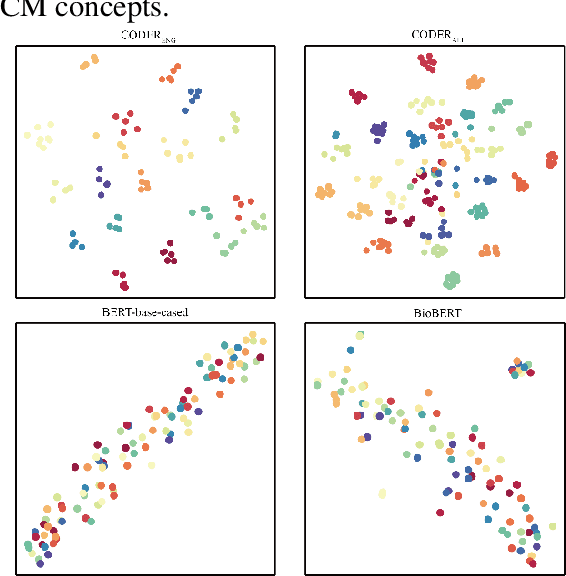
We propose a novel medical term embedding method named CODER, which stands for mediCal knOwledge embeDded tErm Representation. CODER is designed for medical term normalization by providing close vector representations for terms that represent the same or similar concepts with multi-language support. CODER is trained on top of BERT (Devlin et al., 2018) with the innovation that token vector aggregation is trained using relations from the UMLS Metathesaurus (Bodenreider, 2004), which is a comprehensive medical knowledge graph with multi-language support. Training with relations injects medical knowledge into term embeddings and aims to provide better normalization performances and potentially better machine learning features. We evaluated CODER in term normalization, semantic similarity, and relation classification benchmarks, which showed that CODER outperformed various state-of-the-art biomedical word embeddings, concept embeddings, and contextual embeddings.