 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Saliency Spatio-Temporal Interaction Network for Person Re-Identification in Videos
Paper and Code
May 11, 2020
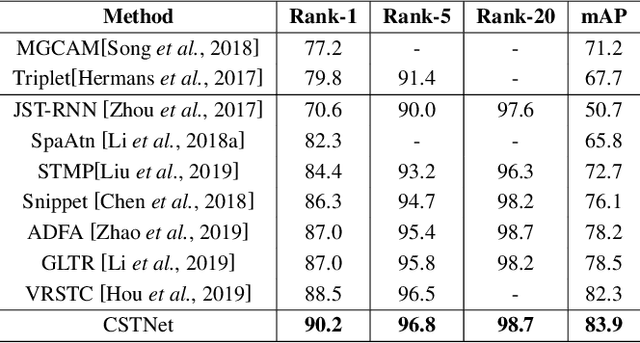
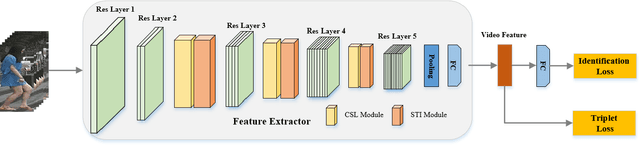
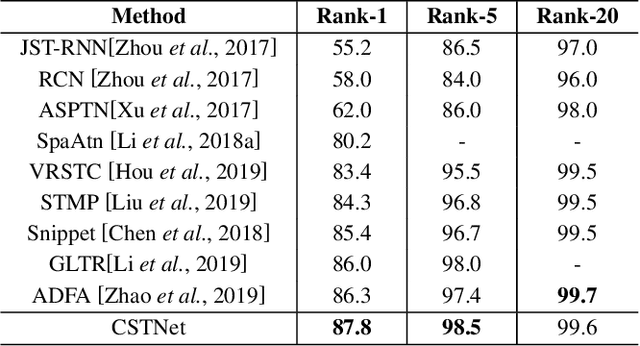
Person re-identification aims at identifying a certain pedestrian across non-overlapping camera networks. Video-based re-identification approaches have gained significant attention recently, expanding image-based approaches by learning features from multiple frames. In this work, we propose a novel Co-Saliency Spatio-Temporal Interaction Network (CSTNet) for person re-identification in videos. It captures the common salient foreground regions among video frames and explores the spatial-temporal long-range context interdependency from such regions, towards learning discriminative pedestrian representation. Specifically, multiple co-saliency learning modules within CSTNet are designed to utilize the correlated information across video frames to extract the salient features from the task-relevant regions and suppress background interference. Moreover, multiple spatialtemporal interaction modules within CSTNet are proposed, which exploit the spatial and temporal long-range context interdependencies on such features and spatial-temporal information correlation, to enhance feature representation. Extensive experiments on two benchmarks have demonstrated the effectiveness of the proposed method.