 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNLL: A Semi-supervised Approach For Continual Noisy Label Learning
Paper and Code
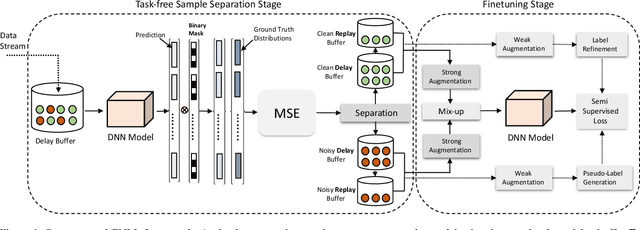
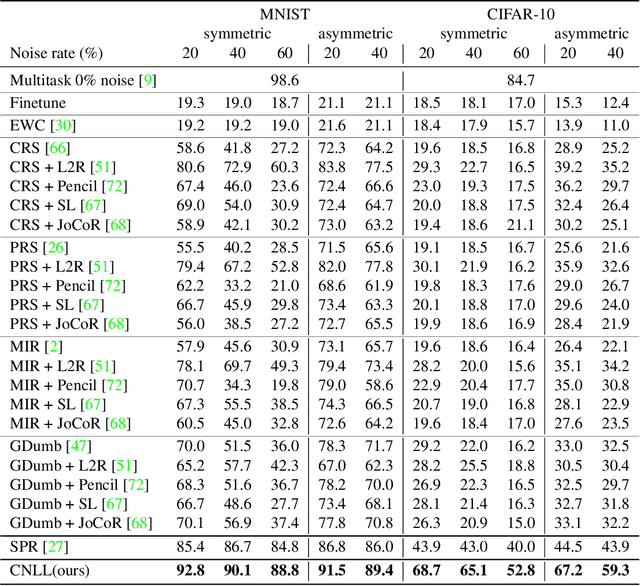
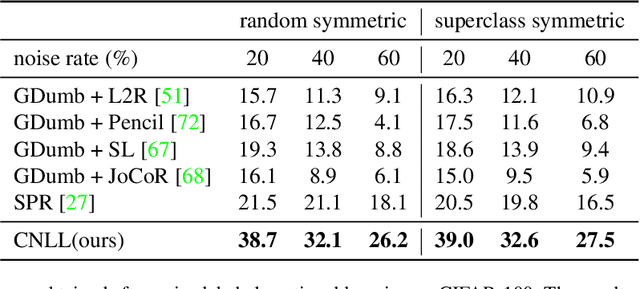
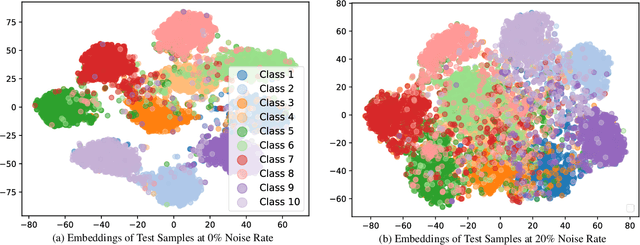
The task of continual learning requires careful design of algorithms that can tackle catastrophic forgetting. However, the noisy label, which is inevitable in a real-world scenario, seems to exacerbate the situation. While very few studies have addressed the issue of continual learning under noisy labels, long training time and complicated training schemes limit their applications in most cases. In contrast, we propose a simple purification technique to effectively cleanse the online data stream that is both cost-effective and more accurate. After purification, we perform fine-tuning in a semi-supervised fashion that ensures the participation of all available samples. Training in this fashion helps us learn a better representation that results in state-of-the-art (SOTA) performance. Through extensive experimentation on 3 benchmark datasets, MNIST, CIFAR10 and CIFAR100, we show the effectiveness of our proposed approach. We achieve a 24.8% performance gain for CIFAR10 with 20% noise over previous SOTA methods. Our code is publicly available.