 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP on Wheels: Zero-Shot Object Navigation as Object Localization and Exploration
Paper and Code

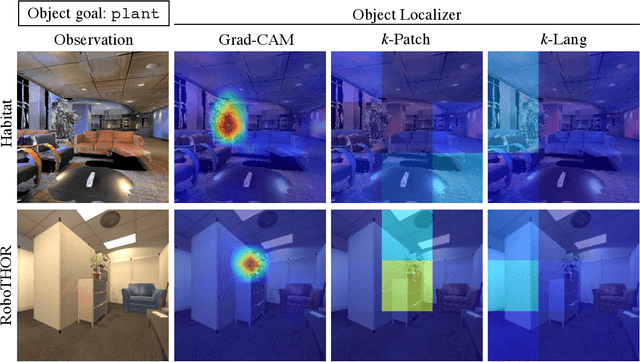
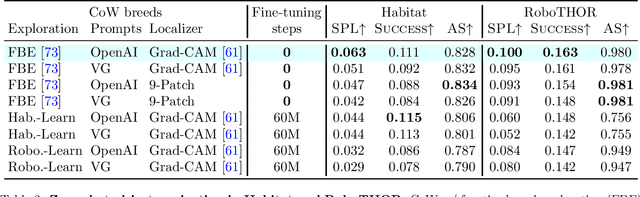
Households across the world contain arbitrary objects: from mate gourds and coffee mugs to sitars and guitars. Considering this diversity, robot perception must handle a large variety of semantic objects without additional fine-tuning to be broadly applicable in homes. Recently, zero-shot models have demonstrated impressive performance in image classification of arbitrary objects (i.e., classifying images at inference with categories not explicitly seen during training). In this paper, we translate the success of zero-shot vision models (e.g., CLIP) to the popular embodied AI task of object navigation. In our setting, an agent must find an arbitrary goal object, specified via text, in unseen environments coming from different datasets. Our key insight is to modularize the task into zero-shot object localization and exploration. Employing this philosophy, we design CLIP on Wheels (CoW) baselines for the task and evaluate each zero-shot model in both Habitat and RoboTHOR simulators. We find that a straightforward CoW, with CLIP-based object localization plus classical exploration, and no additional training, often outperforms learnable approaches in terms of success, efficiency, and robustness to dataset distribution shift. This CoW achieves 6.3% SPL in Habitat and 10.0% SPL in RoboTHOR, when tested zero-shot on all categories. On a subset of four RoboTHOR categories considered in prior work, the same CoW shows a 16.1 percentage point improvement in Success over the learnable state-of-the-art baseline.