Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifier Ensembles for Dialect and Language Variety Identification
Paper and Code
Aug 14, 2018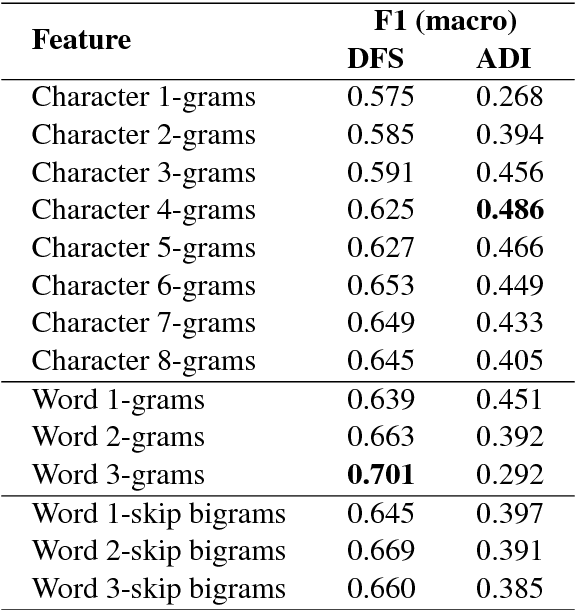
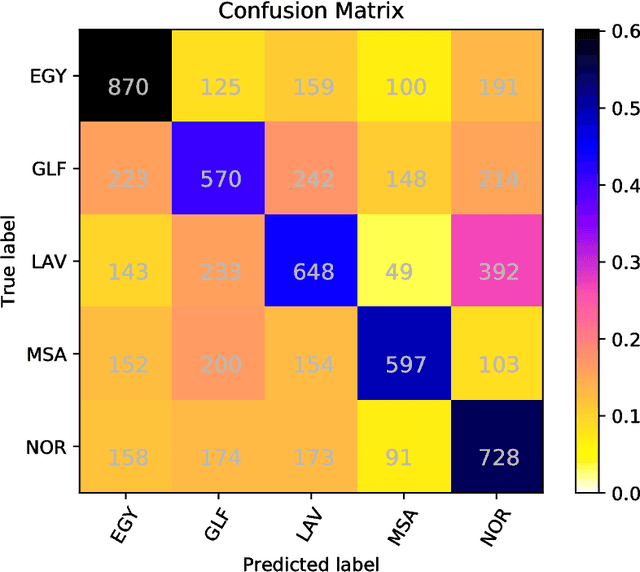
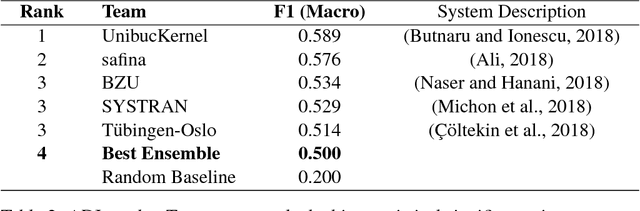
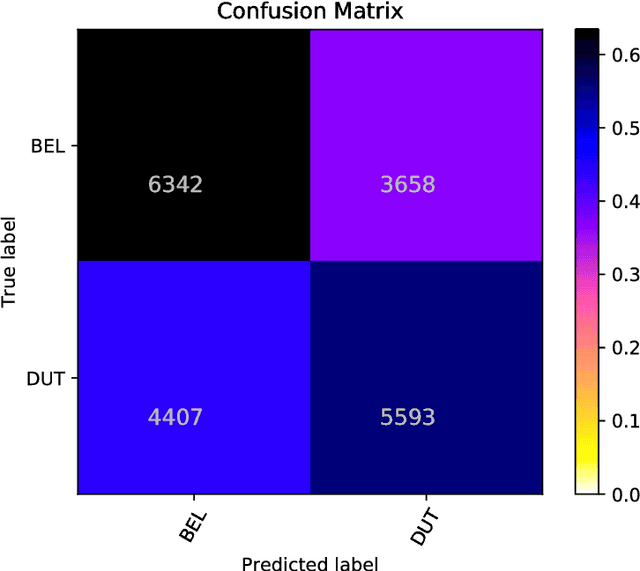
In this paper we present ensemble-based systems for dialect and language variety identification using the datasets made available by the organizers of the VarDial Evaluation Campaign 2018. We present a system developed to discriminate between Flemish and Dutch in subtitles and a system trained to discriminate between four Arabic dialects: Egyptian, Levantine, Gulf, North African, and Modern Standard Arabic in speech broadcasts. Finally, we compare the performance of these two systems with the other systems submitted to the Discriminating between Dutch and Flemish in Subtitles (DFS) and the Arabic Dialect Identification (ADI) shared tasks at VarDial 2018.
View paper on