 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass Impression for Data-free Incremental Learning
Paper and Code
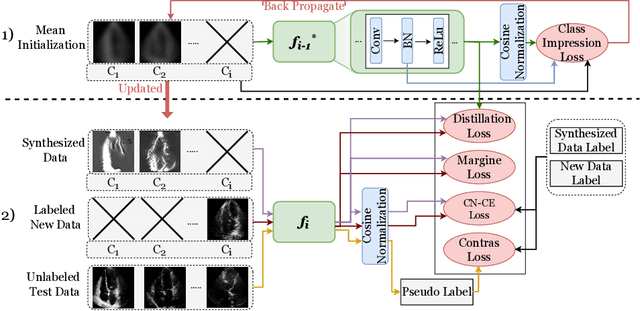
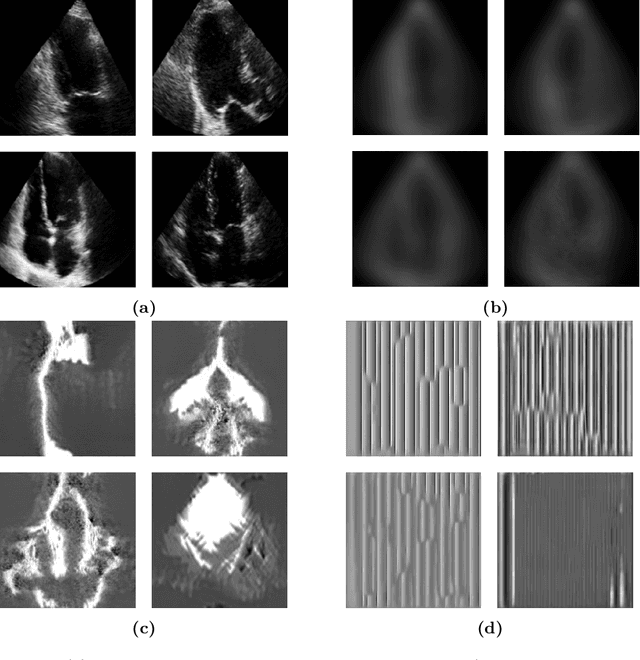
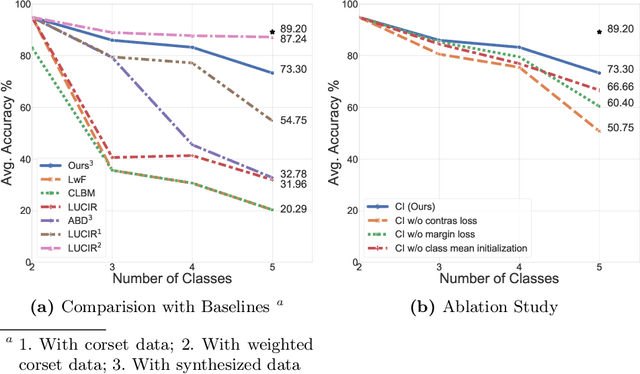
Standard deep learning-based classification approaches require collecting all samples from all classes in advance and are trained offline. This paradigm may not be practical in real-world clinical applications, where new classes are incrementally introduced through the addition of new data. Class incremental learning is a strategy allowing learning from such data. However, a major challenge is catastrophic forgetting, i.e., performance degradation on previous classes when adapting a trained model to new data. Prior methodologies to alleviate this challenge save a portion of training data require perpetual storage of such data that may introduce privacy issues. Here, we propose a novel data-free class incremental learning framework that first synthesizes data from the model trained on previous classes to generate a \ours. Subsequently, it updates the model by combining the synthesized data with new class data. Furthermore, we incorporate a cosine normalized Cross-entropy loss to mitigate the adverse effects of the imbalance, a margin loss to increase separation among previous classes and new ones, and an intra-domain contrastive loss to generalize the model trained on the synthesized data to real data. We compare our proposed framework with state-of-the-art methods in class incremental learning, where we demonstrate improvement in accuracy for the classification of 11,062 echocardiography cine series of patients.