 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCK-Transformer: Commonsense Knowledge Enhanced Transformers for Referring Expression Comprehension
Paper and Code
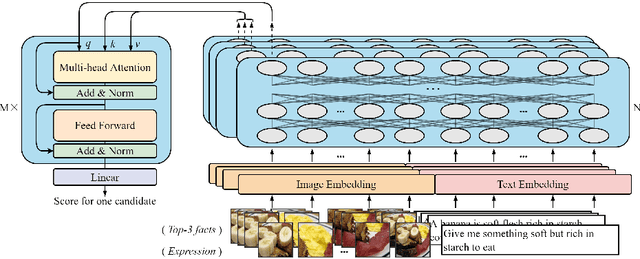
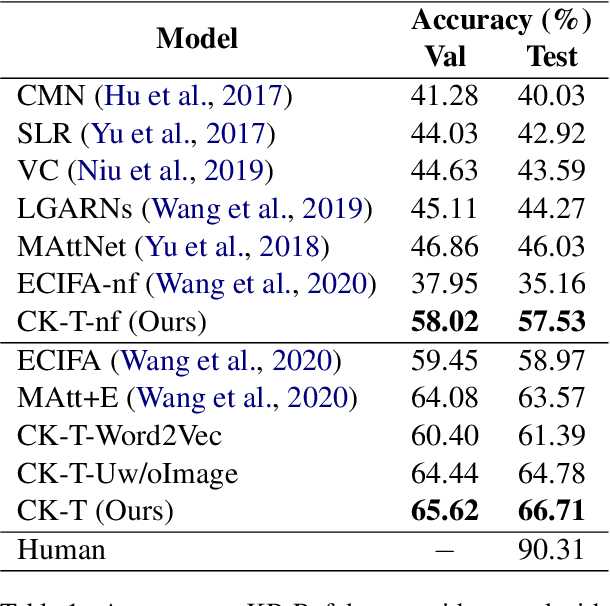
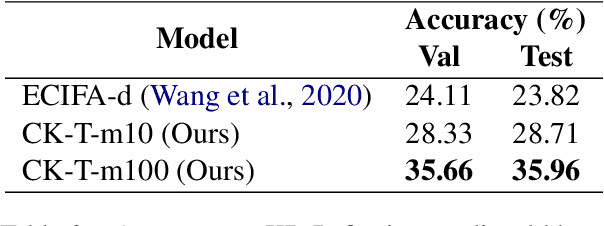
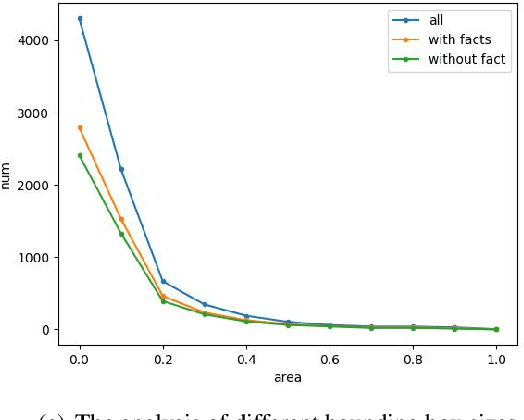
The task of multimodal referring expression comprehension (REC), aiming at localizing an image region described by a natural language expression, has recently received increasing attention within the research comminity. In this paper, we specifically focus on referring expression comprehension with commonsense knowledge (KB-Ref), a task which typically requires reasoning beyond spatial, visual or semantic information. We propose a novel framework for Commonsense Knowledge Enhanced Transformers (CK-Transformer) which effectively integrates commonsense knowledge into the representations of objects in an image, facilitating identification of the target objects referred to by the expressions. We conduct extensive experiments on several benchmarks for the task of KB-Ref. Our results show that the proposed CK-Transformer achieves a new state of the art, with an absolute improvement of 3.14% accuracy over the existing state of the art.