 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChemical Identification and Indexing in PubMed Articles via BERT and Text-to-Text Approaches
Paper and Code
Nov 30, 2021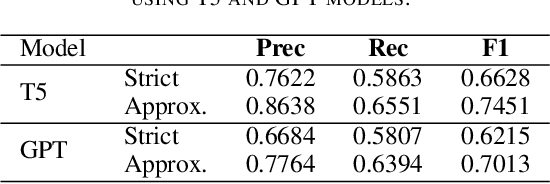

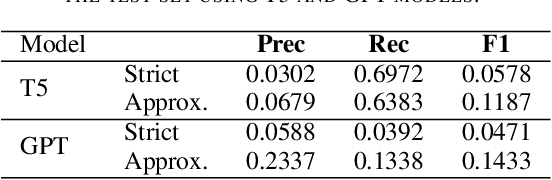
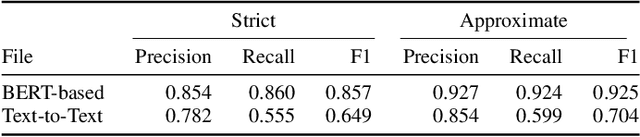
The Biocreative VII Track-2 challenge consists of named entity recognition, entity-linking (or entity-normalization), and topic indexing tasks -- with entities and topics limited to chemicals for this challenge. Named entity recognition is a well-established problem and we achieve our best performance with BERT-based BioMegatron models. We extend our BERT-based approach to the entity linking task. After the second stage of pretraining BioBERT with a metric-learning loss strategy called self-alignment pretraining (SAP), we link entities based on the cosine similarity between their SAP-BioBERT word embeddings. Despite the success of our named entity recognition experiments, we find the chemical indexing task generally more challenging. In addition to conventional NER methods, we attempt both named entity recognition and entity linking with a novel text-to-text or "prompt" based method that uses generative language models such as T5 and GPT. We achieve encouraging results with this new approach.