 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT is a Knowledgeable but Inexperienced Solver: An Investigation of Commonsense Problem in Large Language Models
Paper and Code
Mar 29, 2023
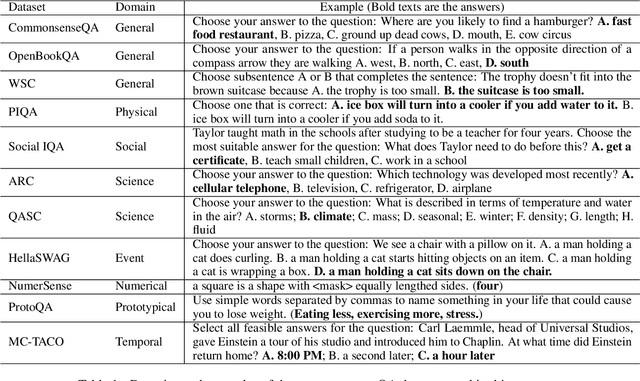

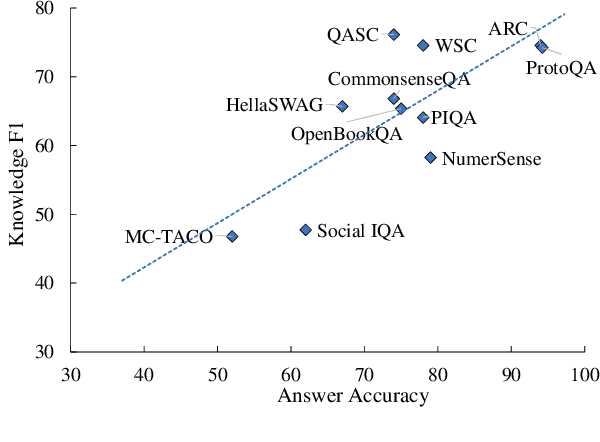
Large language models (LLMs) such as ChatGPT and GPT-4 have made significant progress in NLP. However, their ability to memorize, represent, and leverage commonsense knowledge has been a well-known pain point for LLMs. It remains unclear that: (1) Can GPTs effectively answer commonsense questions? (2) Are GPTs knowledgeable in commonsense? (3) Are GPTs aware of the underlying commonsense knowledge for answering a specific question? (4) Can GPTs effectively leverage commonsense for answering questions? To evaluate the above commonsense problems, we conduct a series of experiments to evaluate ChatGPT's commonsense abilities, and the experimental results show that: (1) GPTs can achieve good QA accuracy in commonsense tasks, while they still struggle with certain types of knowledge. (2) ChatGPT is knowledgeable, and can accurately generate most of the commonsense knowledge using knowledge prompts. (3) Despite its knowledge, ChatGPT is an inexperienced commonsense problem solver, which cannot precisely identify the needed commonsense knowledge for answering a specific question, i.e., ChatGPT does not precisely know what commonsense knowledge is required to answer a question. The above findings raise the need to investigate better mechanisms for utilizing commonsense knowledge in LLMs, such as instruction following, better commonsense guidance, etc.