 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertified Graph Unlearning
Paper and Code

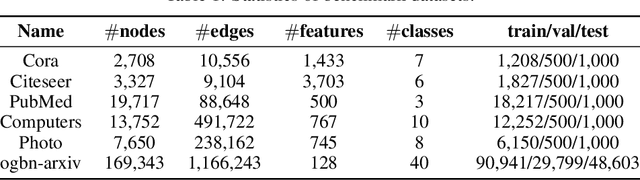


Graph-structured data is ubiquitous in practice and often processed using graph neural networks (GNNs). With the adoption of recent laws ensuring the ``right to be forgotten'', the problem of graph data removal has become of significant importance. To address the problem, we introduce the first known framework for \emph{certified graph unlearning} of GNNs. In contrast to standard machine unlearning, new analytical and heuristic unlearning challenges arise when dealing with complex graph data. First, three different types of unlearning requests need to be considered, including node feature, edge and node unlearning. Second, to establish provable performance guarantees, one needs to address challenges associated with feature mixing during propagation. The underlying analysis is illustrated on the example of simple graph convolutions (SGC) and their generalized PageRank (GPR) extensions, thereby laying the theoretical foundation for certified unlearning of GNNs. Our empirical studies on six benchmark datasets demonstrate excellent performance-complexity trade-offs when compared to complete retraining methods and approaches that do not leverage graph information. For example, when unlearning $20\%$ of the nodes on the Cora dataset, our approach suffers only a $0.1\%$ loss in test accuracy while offering a $4$-fold speed-up compared to complete retraining. Our scheme also outperforms unlearning methods that do not leverage graph information with a $12\%$ increase in test accuracy for a comparable time complexity.