 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCD2CR: Co-reference Resolution Across Documents and Domains
Paper and Code

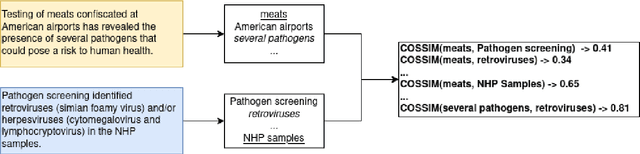

Cross-document co-reference resolution (CDCR) is the task of identifying and linking mentions to entities and concepts across many text documents. Current state-of-the-art models for this task assume that all documents are of the same type (e.g. news articles) or fall under the same theme. However, it is also desirable to perform CDCR across different domains (type or theme). A particular use case we focus on in this paper is the resolution of entities mentioned across scientific work and newspaper articles that discuss them. Identifying the same entities and corresponding concepts in both scientific articles and news can help scientists understand how their work is represented in mainstream media. We propose a new task and English language dataset for cross-document cross-domain co-reference resolution (CD$^2$CR). The task aims to identify links between entities across heterogeneous document types. We show that in this cross-domain, cross-document setting, existing CDCR models do not perform well and we provide a baseline model that outperforms current state-of-the-art CDCR models on CD$^2$CR. Our data set, annotation tool and guidelines as well as our model for cross-document cross-domain co-reference are all supplied as open access open source resources.