Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausally Disentangled Generative Variational AutoEncoder
Paper and Code
Feb 23, 2023
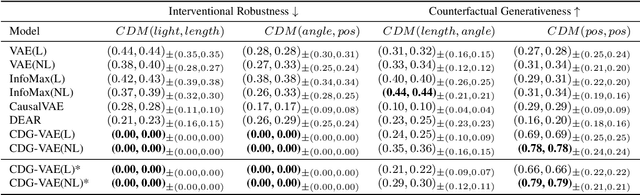
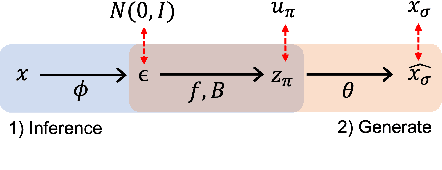
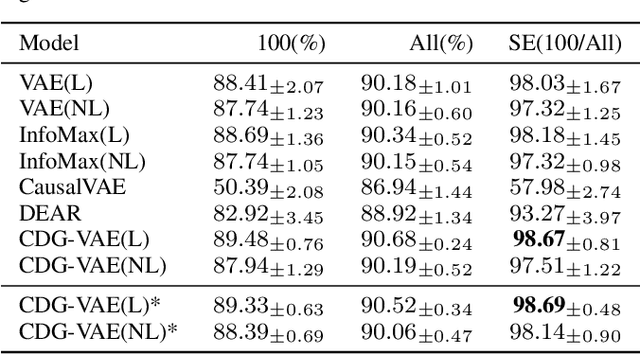
We propose a new supervised learning method for Variational AutoEncoder (VAE) which has a causally disentangled representation and achieves the causally disentangled generation (CDG) simultaneously. In this paper, CDG is defined as a generative model able to decode an output precisely according to the causally disentangled representation. We found that the supervised regularization of the encoder is not enough to obtain a generative model with CDG. Consequently, we explore sufficient and necessary conditions for the decoder and the causal effect to achieve CDG. Moreover, we propose a generalized metric measuring how a model is causally disentangled generative. Numerical results with the image and tabular datasets corroborate our arguments.
* 11 pages for main part, and 17 pages for Appendix
View paper on