 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Discovery as Semi-Supervised Learning
Paper and Code
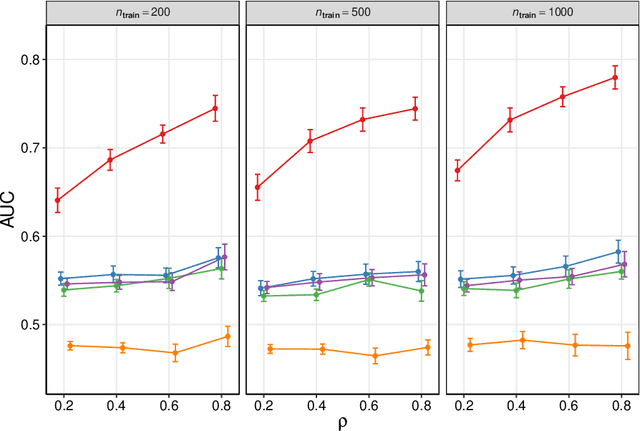
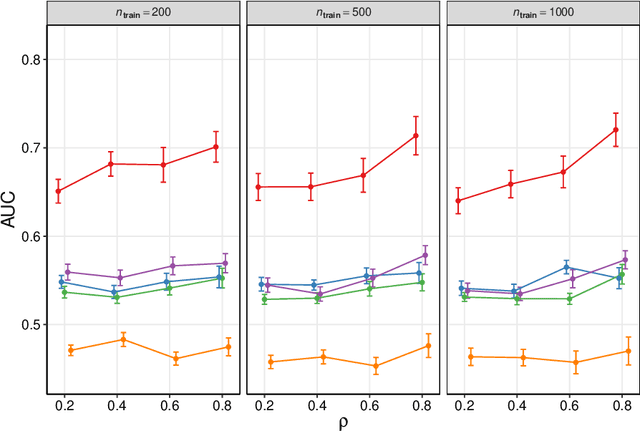
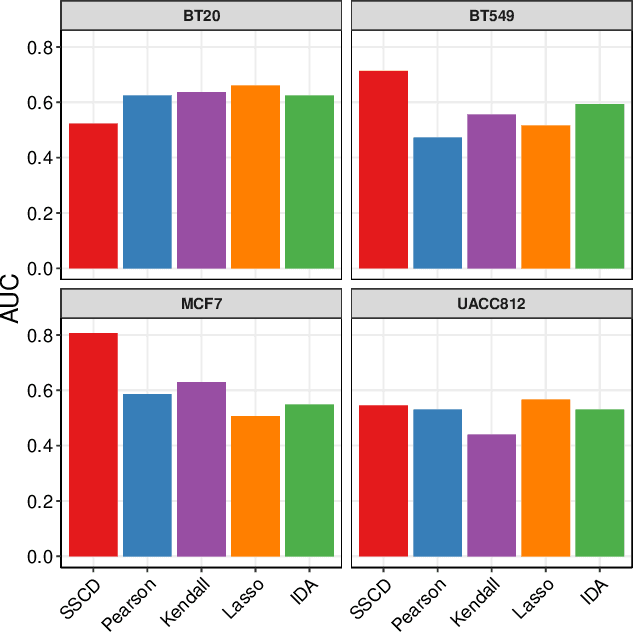
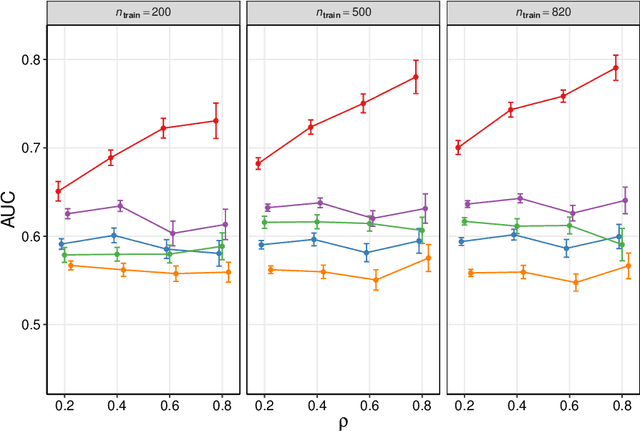
We frame causal discovery as a semi-supervised machine learning task. The idea is to allow direct learning of a causal graph by treating indicators of causal influence between variables as "labels". Available data on the variables of interest are used to provide features for the labelling task. Background knowledge or any available interventional data provide labels on some edges in the graph and the remaining edges are treated as unlabelled. To illustrate the key ideas, we develop a distance-based approach (based on simple bivariate histograms) within a semi-supervised manifold regularization framework. We present empirical results on three different biological datasets (including data where causal effects can be verified by experimental intervention), which demonstrate the efficacy and highly general nature of the approach as well as its simplicity from a user's point of view.