 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascaded Video Generation for Videos In-the-Wild
Paper and Code
Jun 01, 2022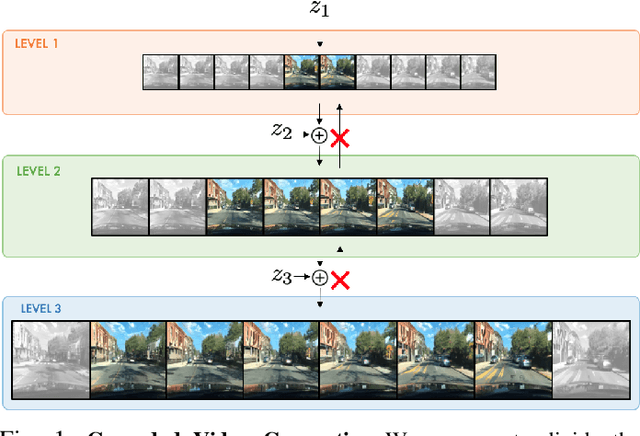

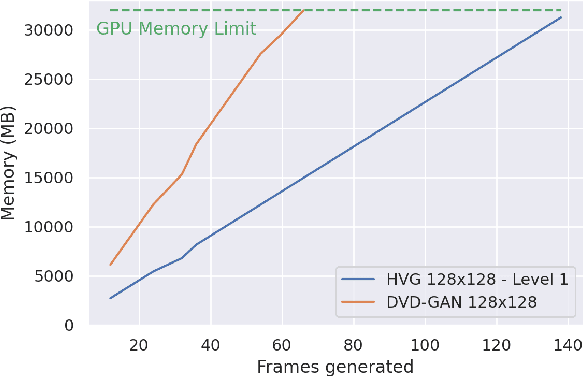

Videos can be created by first outlining a global view of the scene and then adding local details. Inspired by this idea we propose a cascaded model for video generation which follows a coarse to fine approach. First our model generates a low resolution video, establishing the global scene structure, which is then refined by subsequent cascade levels operating at larger resolutions. We train each cascade level sequentially on partial views of the videos, which reduces the computational complexity of our model and makes it scalable to high-resolution videos with many frames. We empirically validate our approach on UCF101 and Kinetics-600, for which our model is competitive with the state-of-the-art. We further demonstrate the scaling capabilities of our model and train a three-level model on the BDD100K dataset which generates 256x256 pixels videos with 48 frames.