 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapacity of the covariance perceptron
Paper and Code
Dec 02, 2019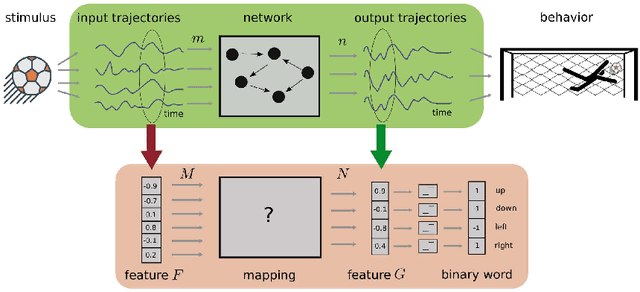
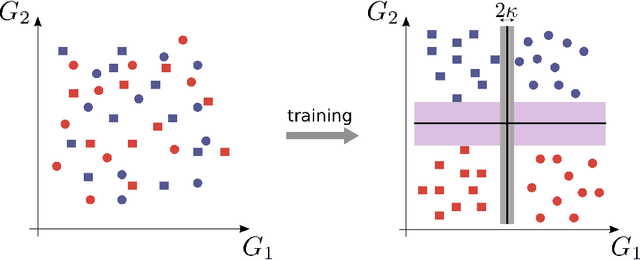
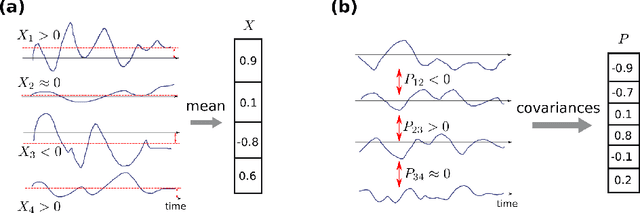
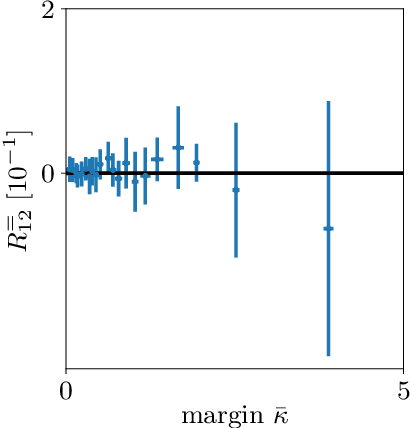
The classical perceptron is a simple neural network that performs a binary classification by a linear mapping between static inputs and outputs and application of a threshold. For small inputs, neural networks in a stationary state also perform an effectively linear input-output transformation, but of an entire time series. Choosing the temporal mean of the time series as the feature for classification, the linear transformation of the network with subsequent thresholding is equivalent to the classical perceptron. Here we show that choosing covariances of time series as the feature for classification maps the neural network to what we call a 'covariance perceptron'; a bilinear mapping between covariances. By extending Gardner's theory of connections to this bilinear problem, using a replica symmetric mean-field theory, we compute the pattern and information capacities of the covariance perceptron in the infinite-size limit. Closed-form expressions reveal superior pattern capacity in the binary classification task compared to the classical perceptron in the case of a high-dimensional input and low-dimensional output. For less convergent networks, the mean perceptron classifies a larger number of stimuli. However, since covariances span a much larger input and output space than means, the amount of stored information in the covariance perceptron exceeds the classical counterpart. For strongly convergent connectivity it is superior by a factor equal to the number of input neurons. Theoretical calculations are validated numerically for finite size systems using a gradient-based optimization of a soft-margin, as well as numerical solvers for the NP hard quadratically constrained quadratic programming problem, to which training can be mapped.