 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Mean Field Control (MFC) Approximate Cooperative Multi Agent Reinforcement Learning (MARL) with Non-Uniform Interaction?
Paper and Code

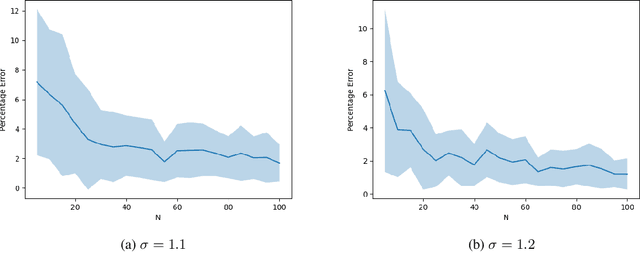
Mean-Field Control (MFC) is a powerful tool to solve Multi-Agent Reinforcement Learning (MARL) problems. Recent studies have shown that MFC can well-approximate MARL when the population size is large and the agents are exchangeable. Unfortunately, the presumption of exchangeability implies that all agents uniformly interact with one another which is not true in many practical scenarios. In this article, we relax the assumption of exchangeability and model the interaction between agents via an arbitrary doubly stochastic matrix. As a result, in our framework, the mean-field `seen' by different agents are different. We prove that, if the reward of each agent is an affine function of the mean-field seen by that agent, then one can approximate such a non-uniform MARL problem via its associated MFC problem within an error of $e=\mathcal{O}(\frac{1}{\sqrt{N}}[\sqrt{|\mathcal{X}|} + \sqrt{|\mathcal{U}|}])$ where $N$ is the population size and $|\mathcal{X}|$, $|\mathcal{U}|$ are the sizes of state and action spaces respectively. Finally, we develop a Natural Policy Gradient (NPG) algorithm that can provide a solution to the non-uniform MARL with an error $\mathcal{O}(\max\{e,\epsilon\})$ and a sample complexity of $\mathcal{O}(\epsilon^{-3})$ for any $\epsilon >0$.