 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Machines Learn Robustly, Privately, and Efficiently?
Paper and Code
Dec 22, 2023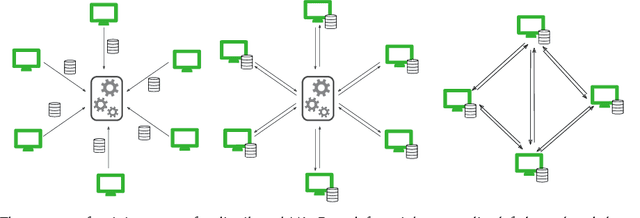
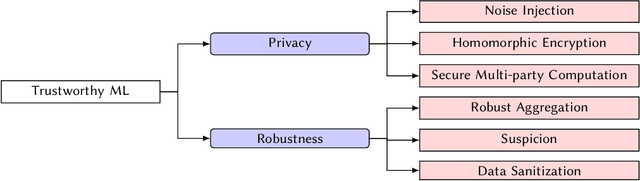
The success of machine learning (ML) applications relies on vast datasets and distributed architectures, which, as they grow, present challenges for ML. In real-world scenarios, where data often contains sensitive information, issues like data poisoning and hardware failures are common. Ensuring privacy and robustness is vital for the broad adoption of ML in public life. This paper examines the costs associated with achieving these objectives in distributed architectures. We overview the meanings of privacy and robustness in distributed ML, and clarify how they can be achieved efficiently in isolation. However, we contend that the integration of these objectives entails a notable compromise in computational efficiency. We delve into this intricate balance, exploring the challenges and solutions for privacy, robustness, and computational efficiency in ML applications.