 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Language Models Be Specific? How?
Paper and Code


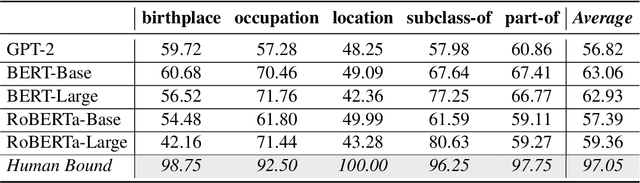
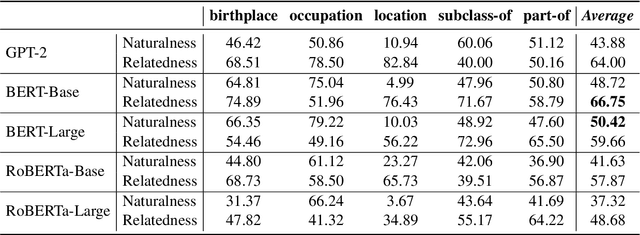
A good speaker not only needs to be correct, but also has the ability to be specific when desired, and so are language models. In this paper, we propose to measure how specific the language of pre-trained language models (PLMs) is. To achieve this, we introduce a novel approach to build a benchmark for specificity testing by forming masked token prediction tasks with prompts. For instance, given ``J. K. Rowling was born in [MASK].'', we want to test whether a more specific answer will be better filled in by PLMs, e.g., Yate instead of England. From our evaluations, we show that existing PLMs have only a slight preference for more specific answers. We identify underlying factors affecting the specificity and design two prompt-based methods to improve the specificity. Results show that the specificity of the models can be improved by the proposed methods without additional training. We believe this work can provide new insights for language modeling and encourage the research community to further explore this important but understudied problem.