 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating Cross-modal Feature for Text-Based Person Searching
Paper and Code
Apr 05, 2023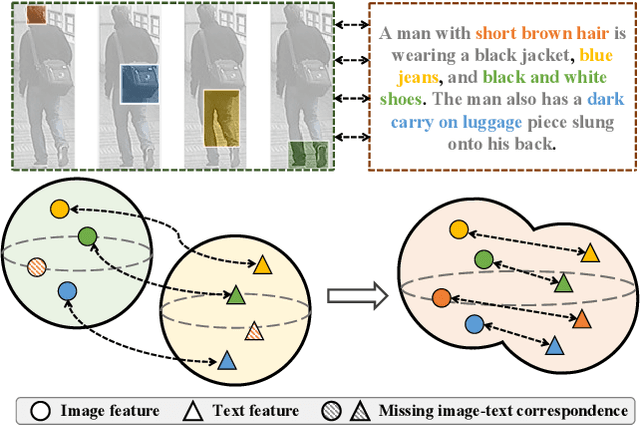



We present a novel and effective method calibrating cross-modal features for text-based person search. Our method is cost-effective and can easily retrieve specific persons with textual captions. Specifically, its architecture is only a dual-encoder and a detachable cross-modal decoder. Without extra multi-level branches or complex interaction modules as the neck following the backbone, our model makes a high-speed inference only based on the dual-encoder. Besides, our method consists of two novel losses to provide fine-grained cross-modal features. A Sew loss takes the quality of textual captions as guidance and aligns features between image and text modalities. A Masking Caption Modeling (MCM) loss uses a masked captions prediction task to establish detailed and generic relationships between textual and visual parts. We show the top results in three popular benchmarks, including CUHK-PEDES, ICFG-PEDES, and RSTPReID. In particular, our method achieves 73.81% Rank@1, 74.25% Rank@1 and 57.35% Rank@1 on them, respectively. In addition, we also validate each component of our method with extensive experiments. We hope our powerful and scalable paradigm will serve as a solid baseline and help ease future research in text-based person search.