 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrate and Prune: Improving Reliability of Lottery Tickets Through Prediction Calibration
Paper and Code
Feb 11, 2020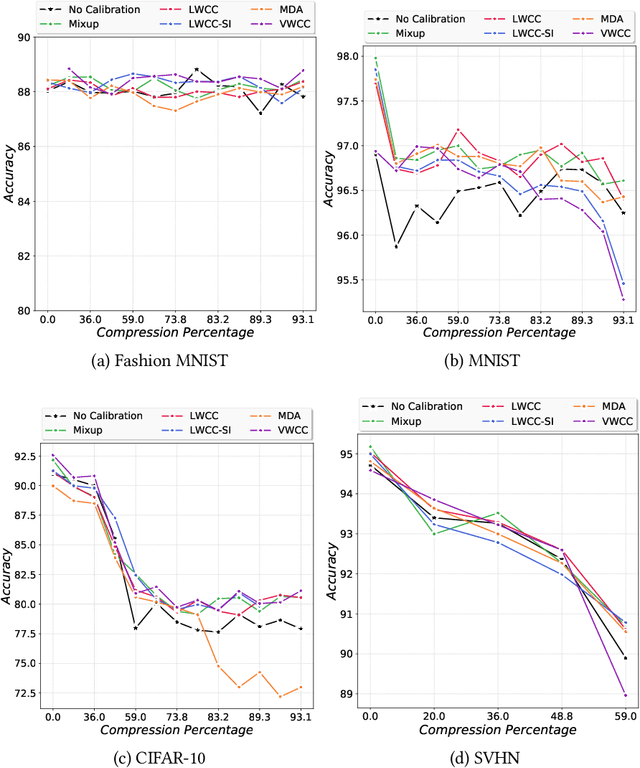
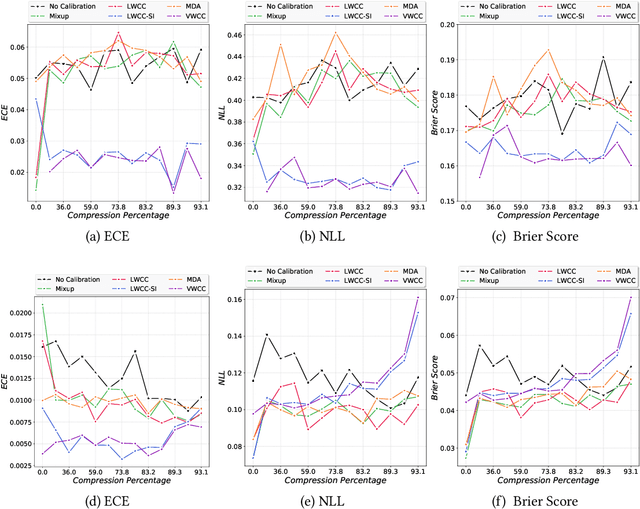
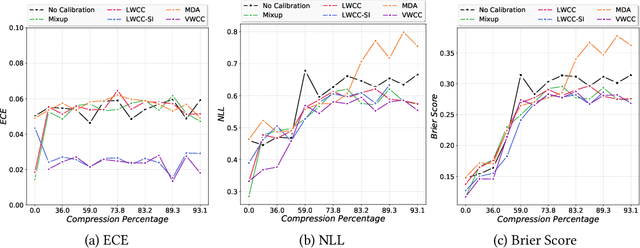
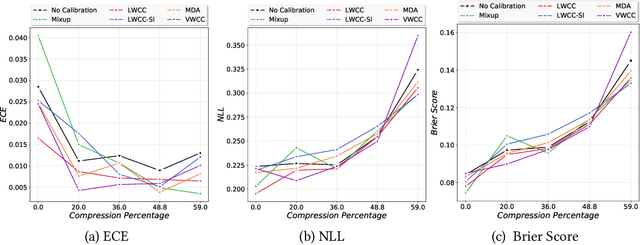
The hypothesis that sub-network initializations (lottery) exist within the initializations of over-parameterized networks, which when trained in isolation produce highly generalizable models, has led to crucial insights into network initialization and has enabled computationally efficient inferencing. In order to realize the full potential of these pruning strategies, particularly when utilized in transfer learning scenarios, it is necessary to understand the behavior of winning tickets when they might overfit to the dataset characteristics. In supervised and semi-supervised learning, prediction calibration is a commonly adopted strategy to handle such inductive biases in models. In this paper, we study the impact of incorporating calibration strategies during model training on the quality of the resulting lottery tickets, using several evaluation metrics. More specifically, we incorporate a suite of calibration strategies to different combinations of architectures and datasets, and evaluate the fidelity of sub-networks retrained based on winning tickets. Furthermore, we report the generalization performance of tickets across distributional shifts, when the inductive biases are explicitly controlled using calibration mechanisms. Finally, we provide key insights and recommendations for obtaining reliable lottery tickets, which we demonstrate to achieve improved generalization.