 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBypass Network for Semantics Driven Image Paragraph Captioning
Paper and Code


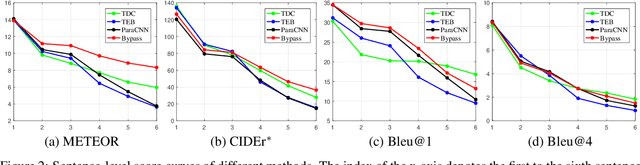

Image paragraph captioning aims to describe a given image with a sequence of coherent sentences. Most existing methods model the coherence through the topic transition that dynamically infers a topic vector from preceding sentences. However, these methods still suffer from immediate or delayed repetitions in generated paragraphs because (i) the entanglement of syntax and semantics distracts the topic vector from attending pertinent visual regions; (ii) there are few constraints or rewards for learning long-range transitions. In this paper, we propose a bypass network that separately models semantics and linguistic syntax of preceding sentences. Specifically, the proposed model consists of two main modules, i.e. a topic transition module and a sentence generation module. The former takes previous semantic vectors as queries and applies attention mechanism on regional features to acquire the next topic vector, which reduces immediate repetition by eliminating linguistics. The latter decodes the topic vector and the preceding syntax state to produce the following sentence. To further reduce delayed repetition in generated paragraphs, we devise a replacement-based reward for the REINFORCE training. Comprehensive experiments on the widely used benchmark demonstrate the superiority of the proposed model over the state of the art for coherence while maintaining high accuracy.