 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBViT: Broad Attention based Vision Transformer
Paper and Code
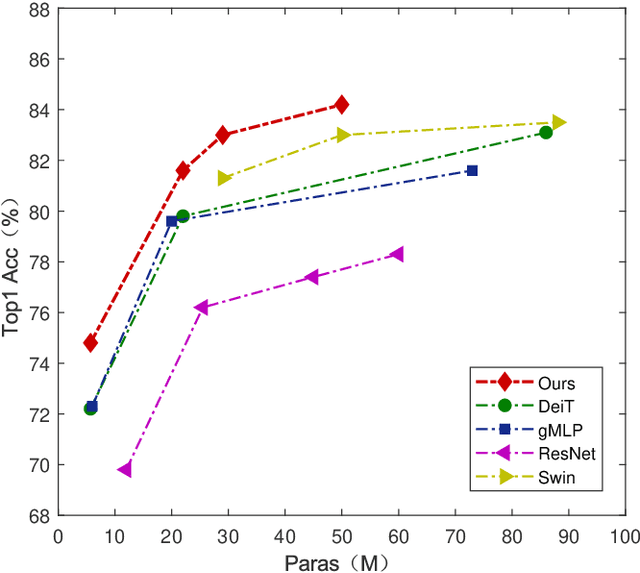
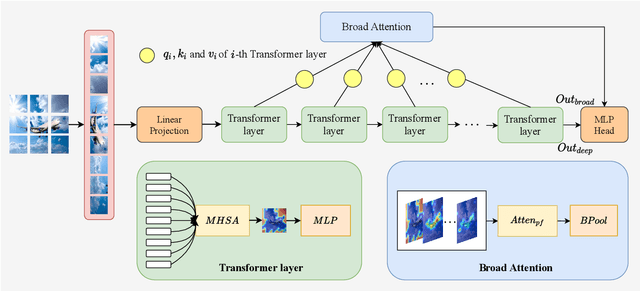
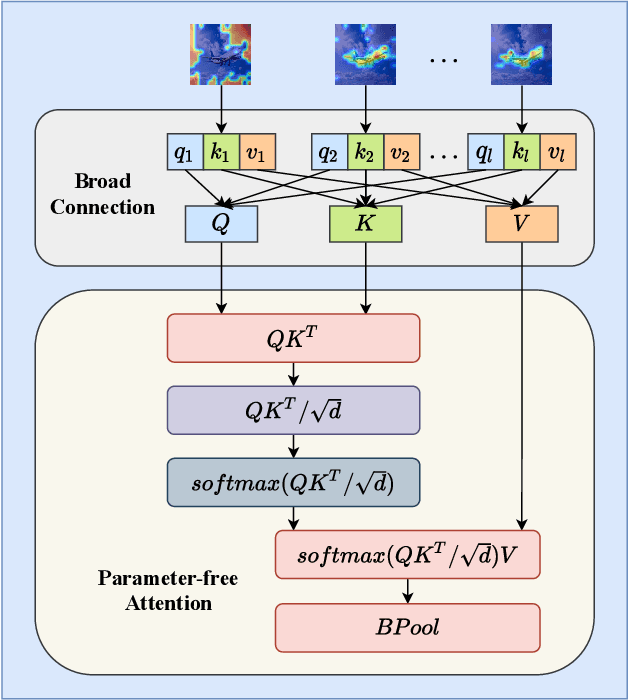
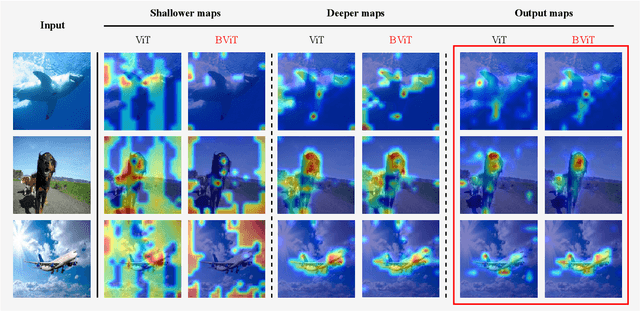
Recent works have demonstrated that transformer can achieve promising performance in computer vision, by exploiting the relationship among image patches with self-attention. While they only consider the attention in a single feature layer, but ignore the complementarity of attention in different levels. In this paper, we propose the broad attention to improve the performance by incorporating the attention relationship of different layers for vision transformer, which is called BViT. The broad attention is implemented by broad connection and parameter-free attention. Broad connection of each transformer layer promotes the transmission and integration of information for BViT. Without introducing additional trainable parameters, parameter-free attention jointly focuses on the already available attention information in different layers for extracting useful information and building their relationship. Experiments on image classification tasks demonstrate that BViT delivers state-of-the-art accuracy of 74.8\%/81.6\% top-1 accuracy on ImageNet with 5M/22M parameters. Moreover, we transfer BViT to downstream object recognition benchmarks to achieve 98.9\% and 89.9\% on CIFAR10 and CIFAR100 respectively that exceed ViT with fewer parameters. For the generalization test, the broad attention in Swin Transformer and T2T-ViT also bring an improvement of more than 1\%. To sum up, broad attention is promising to promote the performance of attention based models. Code and pre-trained models are available at https://github.com/DRL-CASIA/Broad_ViT.