 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Task-Oriented Visual Dialog Systems Through Alternative Optimization Between Dialog Policy and Language Generation
Paper and Code
Sep 06, 2019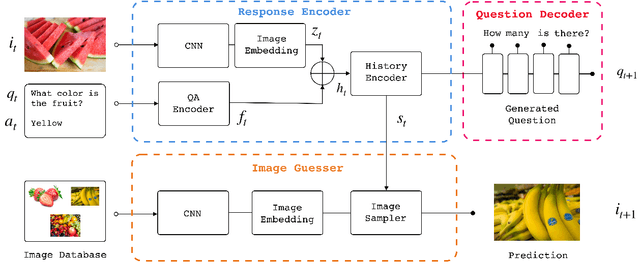

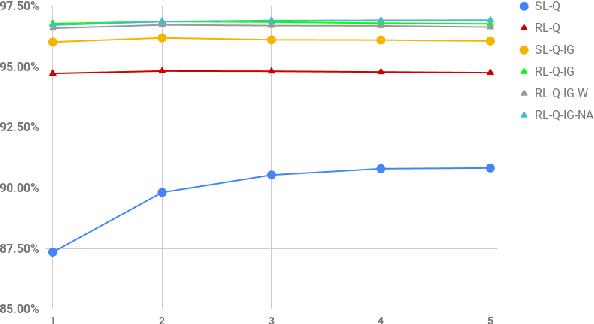
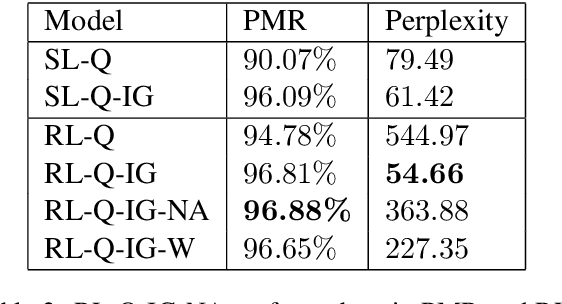
Reinforcement learning (RL) is an effective approach to learn an optimal dialog policy for task-oriented visual dialog systems. A common practice is to apply RL on a neural sequence-to-sequence (seq2seq) framework with the action space being the output vocabulary in the decoder. However, it is difficult to design a reward function that can achieve a balance between learning an effective policy and generating a natural dialog response. This paper proposes a novel framework that alternatively trains a RL policy for image guessing and a supervised seq2seq model to improve dialog generation quality. We evaluate our framework on the GuessWhich task and the framework achieves the state-of-the-art performance in both task completion and dialog quality.