 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Heterogeneous Cloud System for Machine Learning Inference
Paper and Code
Oct 15, 2022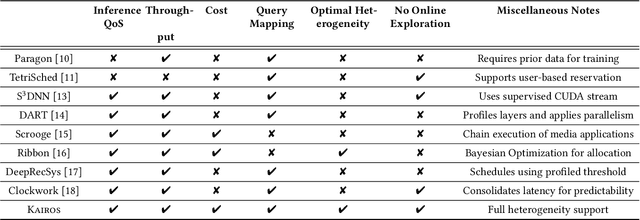
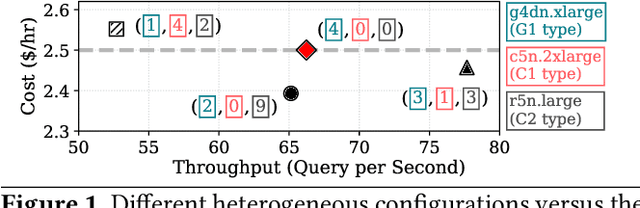
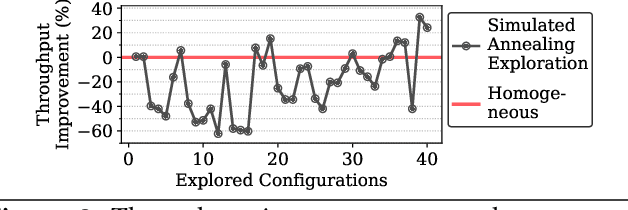

Online inference is becoming a key service product for many businesses, deployed in cloud platforms to meet customer demands. Despite their revenue-generation capability, these services need to operate under tight Quality-of-Service (QoS) and cost budget constraints. This paper introduces KAIROS, a novel runtime framework that maximizes the query throughput while meeting QoS target and a cost budget. KAIROS designs and implements novel techniques to build a pool of heterogeneous compute hardware without online exploration overhead, and distribute inference queries optimally at runtime. Our evaluation using industry-grade deep learning (DL) models shows that KAIROS yields up to 2X the throughput of an optimal homogeneous solution, and outperforms state-of-the-art schemes by up to 70%, despite advantageous implementations of the competing schemes to ignore their exploration overhead.