 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBroad Context Language Modeling as Reading Comprehension
Paper and Code
Feb 16, 2017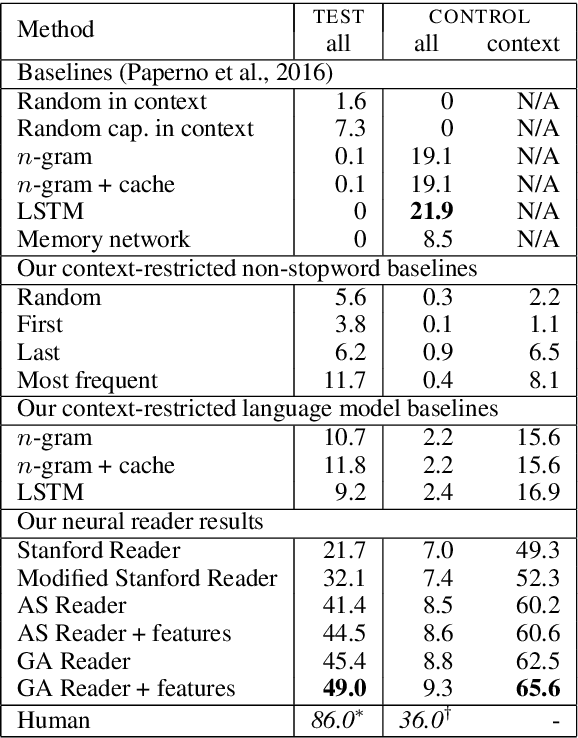

Progress in text understanding has been driven by large datasets that test particular capabilities, like recent datasets for reading comprehension (Hermann et al., 2015). We focus here on the LAMBADA dataset (Paperno et al., 2016), a word prediction task requiring broader context than the immediate sentence. We view LAMBADA as a reading comprehension problem and apply comprehension models based on neural networks. Though these models are constrained to choose a word from the context, they improve the state of the art on LAMBADA from 7.3% to 49%. We analyze 100 instances, finding that neural network readers perform well in cases that involve selecting a name from the context based on dialogue or discourse cues but struggle when coreference resolution or external knowledge is needed.