 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Generalization Gaps in High Content Imaging Through Online Self-Supervised Domain Adaptation
Paper and Code
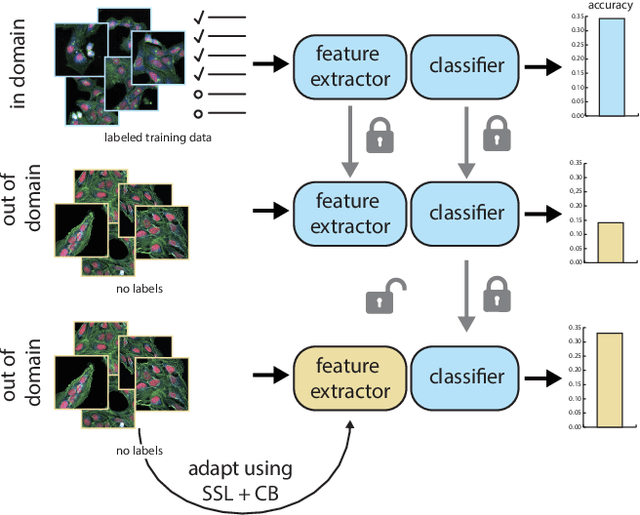
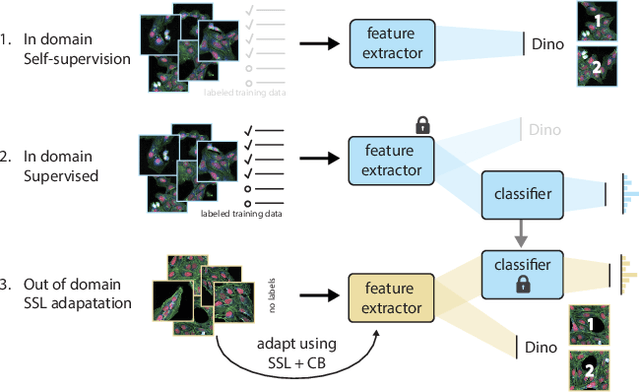
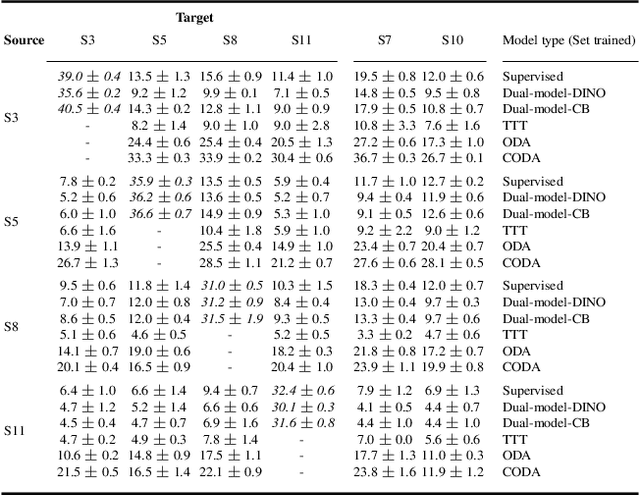
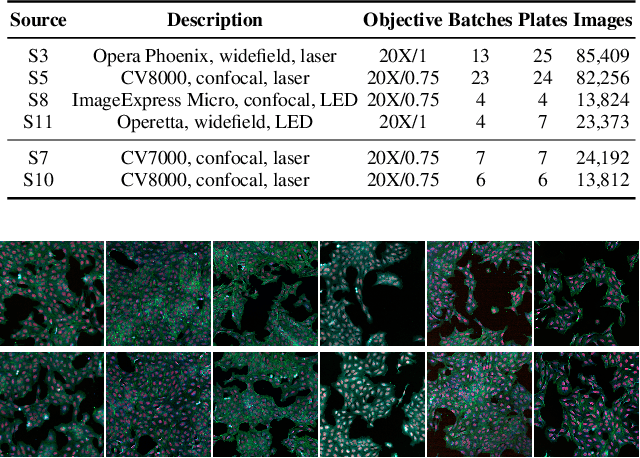
High Content Imaging (HCI) plays a vital role in modern drug discovery and development pipelines, facilitating various stages from hit identification to candidate drug characterization. Applying machine learning models to these datasets can prove challenging as they typically consist of multiple batches, affected by experimental variation, especially if different imaging equipment have been used. Moreover, as new data arrive, it is preferable that they are analyzed in an online fashion. To overcome this, we propose CODA, an online self-supervised domain adaptation approach. CODA divides the classifier's role into a generic feature extractor and a task-specific model. We adapt the feature extractor's weights to the new domain using cross-batch self-supervision while keeping the task-specific model unchanged. Our results demonstrate that this strategy significantly reduces the generalization gap, achieving up to a 300% improvement when applied to data from different labs utilizing different microscopes. CODA can be applied to new, unlabeled out-of-domain data sources of different sizes, from a single plate to multiple experimental batches.