 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridge the Modality and Capacity Gaps in Vision-Language Model Selection
Paper and Code
Mar 20, 2024

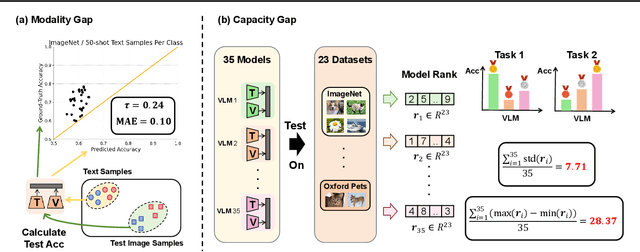

Vision Language Models (VLMs) excel in zero-shot image classification by pairing images with textual category names. The expanding variety of Pre-Trained VLMs enhances the likelihood of identifying a suitable VLM for specific tasks. Thus, a promising zero-shot image classification strategy is selecting the most appropriate Pre-Trained VLM from the VLM Zoo, relying solely on the text data of the target dataset without access to the dataset's images. In this paper, we analyze two inherent challenges in assessing the ability of a VLM in this Language-Only VLM selection: the "Modality Gap" -- the disparity in VLM's embeddings across two different modalities, making text a less reliable substitute for images; and the "Capability Gap" -- the discrepancy between the VLM's overall ranking and its ranking for target dataset, hindering direct prediction of a model's dataset-specific performance from its general performance. We propose VLM Selection With gAp Bridging (SWAB) to mitigate the negative impact of these two gaps. SWAB first adopts optimal transport to capture the relevance between open-source datasets and target dataset with a transportation matrix. It then uses this matrix to transfer useful statistics of VLMs from open-source datasets to the target dataset for bridging those two gaps and enhancing the VLM's capacity estimation for VLM selection. Experiments across various VLMs and image classification datasets validate SWAB's effectiveness.