 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBregman Proximal Framework for Deep Linear Neural Networks
Paper and Code
Oct 08, 2019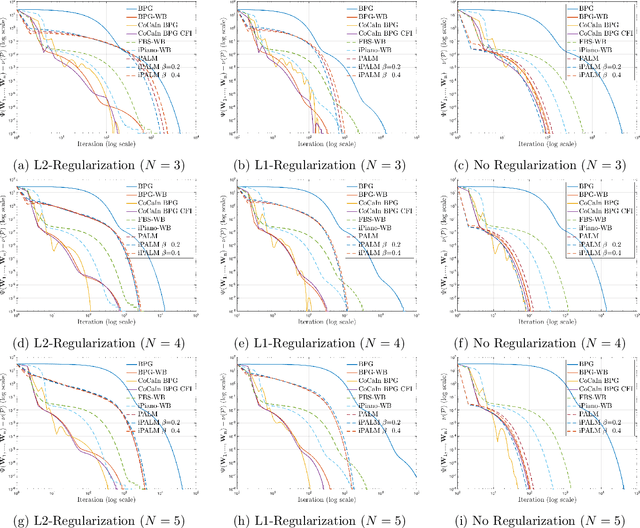
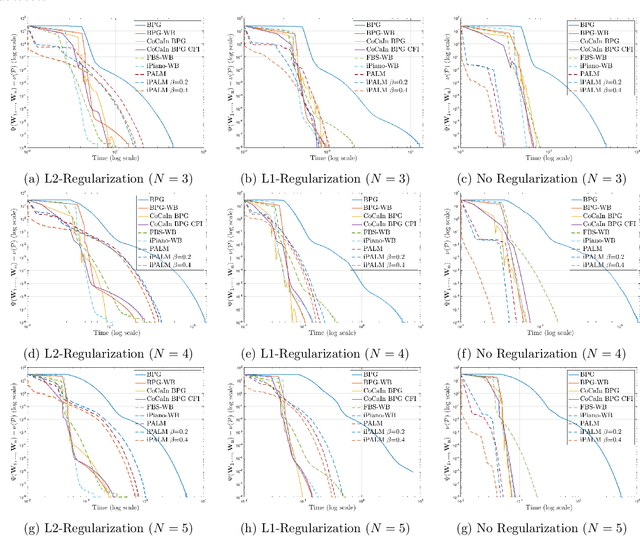
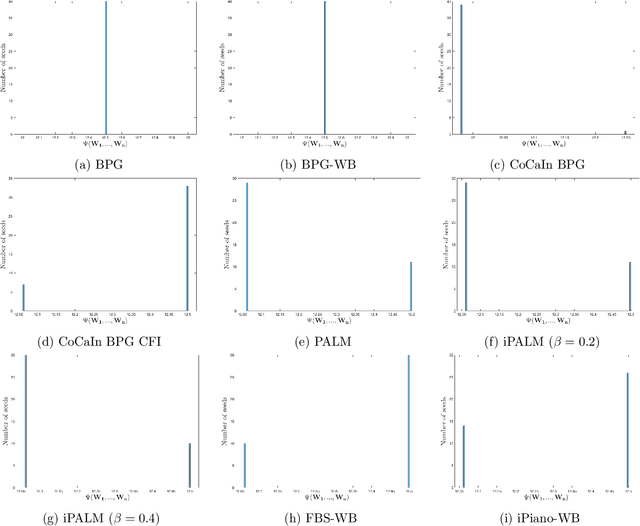

A typical assumption for the analysis of first order optimization methods is the Lipschitz continuity of the gradient of the objective function. However, for many practical applications this assumption is violated, including loss functions in deep learning. To overcome this issue, certain extensions based on generalized proximity measures known as Bregman distances were introduced. This initiated the development of the Bregman proximal gradient (BPG) algorithm and an inertial variant (momentum based) CoCaIn BPG, which however rely on problem dependent Bregman distances. In this paper, we develop Bregman distances for using BPG methods to train Deep Linear Neural Networks. The main implications of our results are strong convergence guarantees for these algorithms. We also propose several strategies for their efficient implementation, for example, closed form updates and a closed form expression for the inertial parameter of CoCaIn BPG. Moreover, the BPG method requires neither diminishing step sizes nor line search, unlike its corresponding Euclidean version. We numerically illustrate the competitiveness of the proposed methods compared to existing state of the art schemes.