 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Softmax Bottleneck via Learnable Monotonic Pointwise Non-linearities
Paper and Code

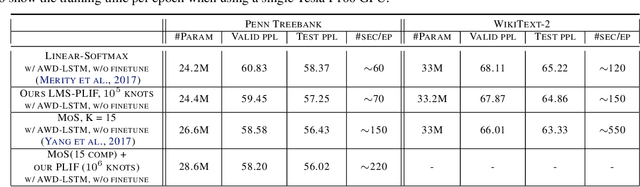
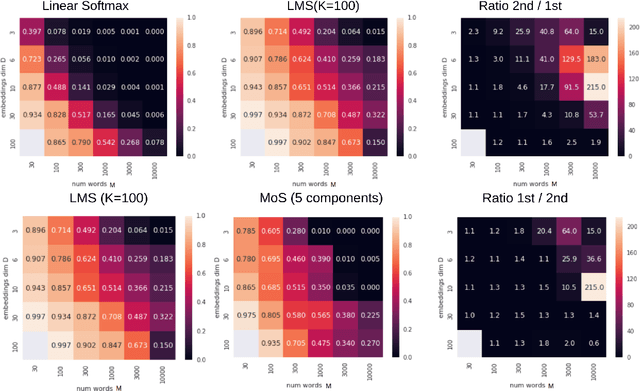
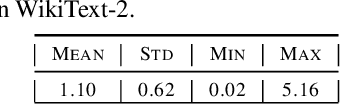
The softmax function on top of a final linear layer is the de facto method to output probability distributions in neural networks. In many applications such as language models or text generation, this model has to produce distributions over large output vocabularies. Recently, this has been shown to have limited representational capacity due to its connection with the rank bottleneck in matrix factorization. However, little is known about the limitations of linear-softmax for quantities of practical interest such as cross entropy or mode estimation, a direction that we theoretically and empirically explore here. As an efficient and effective solution to alleviate this issue, we propose to learn parametric monotonic functions on top of the logits. We theoretically investigate the rank increasing capabilities of such monotonic functions. Empirically, our method improves in two different quality metrics over the traditional softmax-linear layer in synthetic and real language model experiments, adding little time or memory overhead, while being comparable to the more computationally expensive mixture of softmaxes.