 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounding Membership Inference
Paper and Code
Feb 24, 2022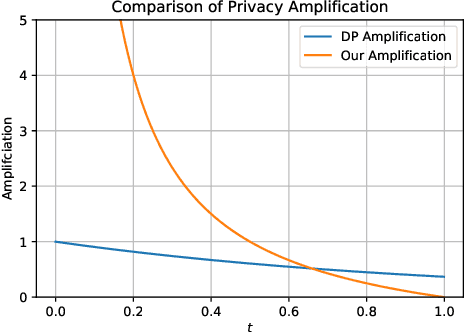

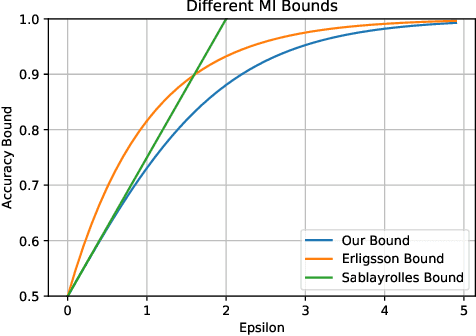
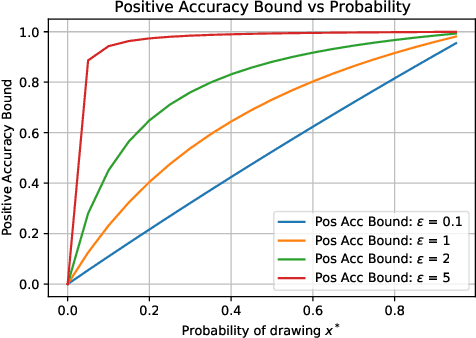
Differential Privacy (DP) is the de facto standard for reasoning about the privacy guarantees of a training algorithm. Despite the empirical observation that DP reduces the vulnerability of models to existing membership inference (MI) attacks, a theoretical underpinning as to why this is the case is largely missing in the literature. In practice, this means that models need to be trained with DP guarantees that greatly decrease their accuracy. In this paper, we provide a tighter bound on the accuracy of any MI adversary when a training algorithm provides $\epsilon$-DP. Our bound informs the design of a novel privacy amplification scheme, where an effective training set is sub-sampled from a larger set prior to the beginning of training, to greatly reduce the bound on MI accuracy. As a result, our scheme enables $\epsilon$-DP users to employ looser DP guarantees when training their model to limit the success of any MI adversary; this ensures that the model's accuracy is less impacted by the privacy guarantee. Finally, we discuss implications of our MI bound on the field of machine unlearning.