 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBorrowing From the Future: Addressing Double Sampling in Model-free Control
Paper and Code
Jun 11, 2020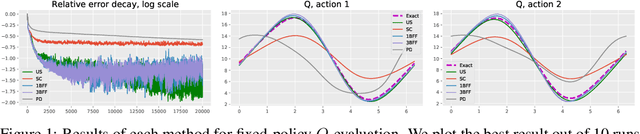
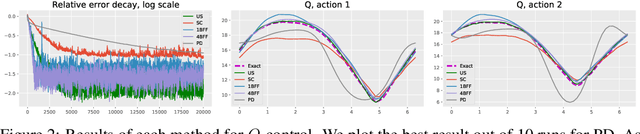
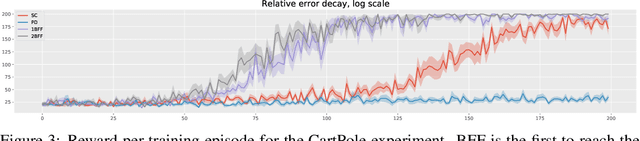

In model-free reinforcement learning, the temporal difference method and its variants become unstable when combined with nonlinear function approximations. Bellman residual minimization with stochastic gradient descent (SGD) is more stable, but it suffers from the double sampling problem: given the current state, two independent samples for the next state are required, but often only one sample is available. Recently, the authors of [Zhu et al, 2020] introduced the borrowing from the future (BFF) algorithm to address this issue for the prediction problem. The main idea is to borrow extra randomness from the future to approximately re-sample the next state when the underlying dynamics of the problem are sufficiently smooth. This paper extends the BFF algorithm to action-value function based model-free control. We prove that BFF is close to unbiased SGD when the underlying dynamics vary slowly with respect to actions. We confirm our theoretical findings with numerical simulations.