 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapped Representation Learning on Graphs
Paper and Code
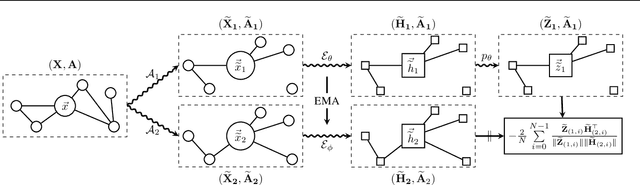
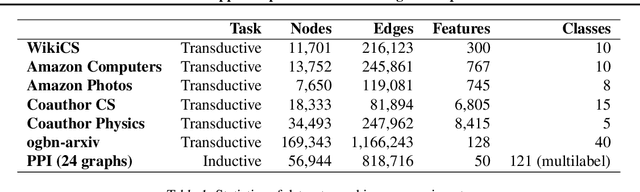
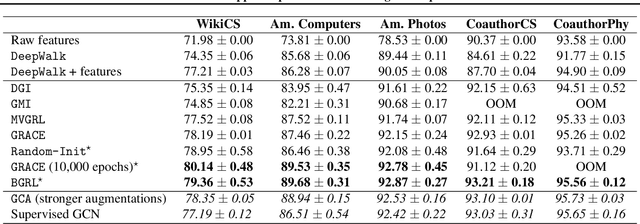
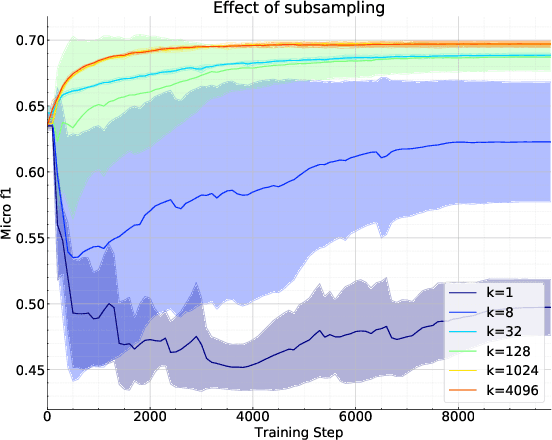
Current state-of-the-art self-supervised learning methods for graph neural networks (GNNs) are based on contrastive learning. As such, they heavily depend on the construction of augmentations and negative examples. For example, on the standard PPI benchmark, increasing the number of negative pairs improves performance, thereby requiring computation and memory cost quadratic in the number of nodes to achieve peak performance. Inspired by BYOL, a recently introduced method for self-supervised learning that does not require negative pairs, we present Bootstrapped Graph Latents, BGRL, a self-supervised graph representation method that gets rid of this potentially quadratic bottleneck. BGRL outperforms or matches the previous unsupervised state-of-the-art results on several established benchmark datasets. Moreover, it enables the effective usage of graph attentional (GAT) encoders, allowing us to further improve the state of the art. In particular on the PPI dataset, using GAT as an encoder we achieve state-of-the-art 70.49% Micro-F1, using the linear evaluation protocol. On all other datasets under consideration, our model is competitive with the equivalent supervised GNN results, often exceeding them.