 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoilerplate Removal using a Neural Sequence Labeling Model
Paper and Code

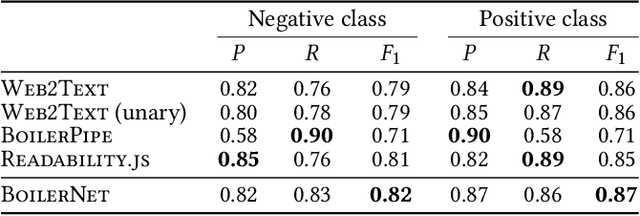
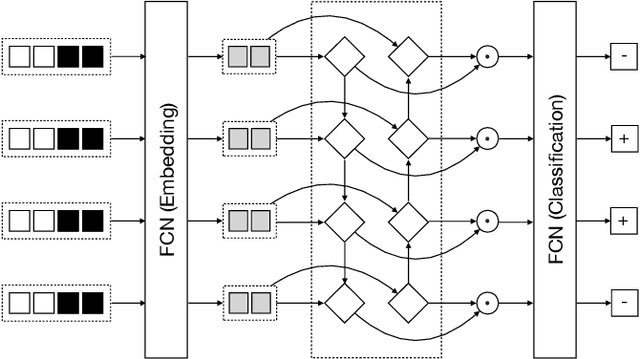
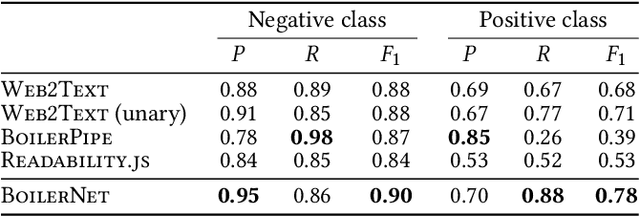
The extraction of main content from web pages is an important task for numerous applications, ranging from usability aspects, like reader views for news articles in web browsers, to information retrieval or natural language processing. Existing approaches are lacking as they rely on large amounts of hand-crafted features for classification. This results in models that are tailored to a specific distribution of web pages, e.g. from a certain time frame, but lack in generalization power. We propose a neural sequence labeling model that does not rely on any hand-crafted features but takes only the HTML tags and words that appear in a web page as input. This allows us to present a browser extension which highlights the content of arbitrary web pages directly within the browser using our model. In addition, we create a new, more current dataset to show that our model is able to adapt to changes in the structure of web pages and outperform the state-of-the-art model.