 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlock Walsh-Hadamard Transform Based Binary Layers in Deep Neural Networks
Paper and Code
Jan 28, 2022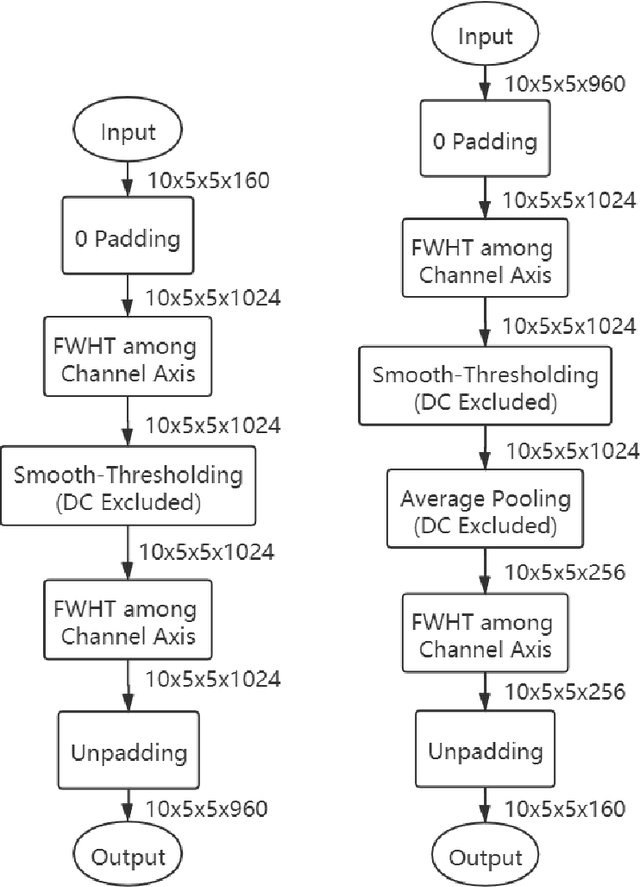
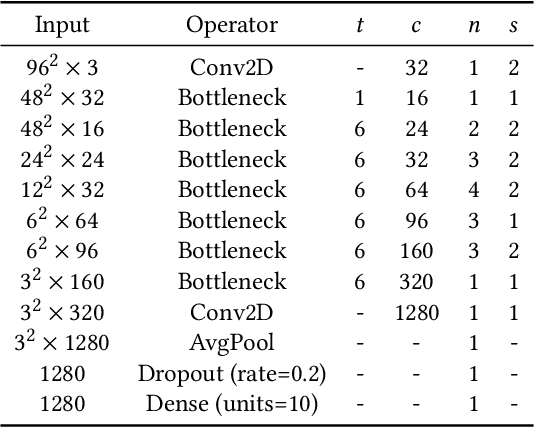
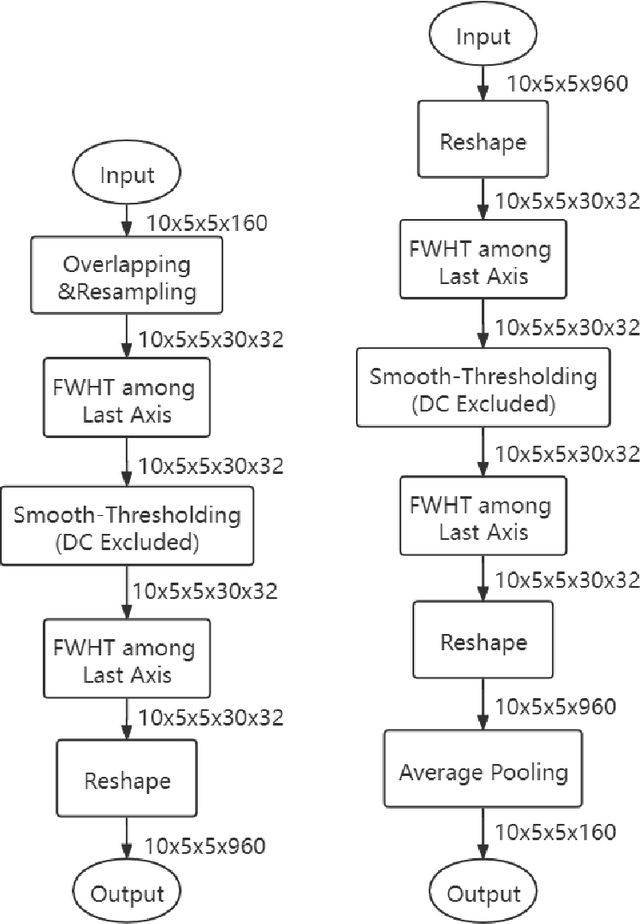
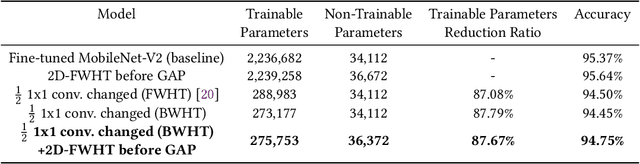
Convolution has been the core operation of modern deep neural networks. It is well-known that convolutions can be implemented in the Fourier Transform domain. In this paper, we propose to use binary block Walsh-Hadamard transform (WHT) instead of the Fourier transform. We use WHT-based binary layers to replace some of the regular convolution layers in deep neural networks. We utilize both one-dimensional (1-D) and two-dimensional (2-D) binary WHTs in this paper. In both 1-D and 2-D layers, we compute the binary WHT of the input feature map and denoise the WHT domain coefficients using a nonlinearity which is obtained by combining soft-thresholding with the tanh function. After denoising, we compute the inverse WHT. We use 1D-WHT to replace the $1\times 1$ convolutional layers, and 2D-WHT layers can replace the 3$\times$3 convolution layers and Squeeze-and-Excite layers. 2D-WHT layers with trainable weights can be also inserted before the Global Average Pooling (GAP) layers to assist the dense layers. In this way, we can reduce the number of trainable parameters significantly with a slight decrease in trainable parameters. In this paper, we implement the WHT layers into MobileNet-V2, MobileNet-V3-Large, and ResNet to reduce the number of parameters significantly with negligible accuracy loss. Moreover, according to our speed test, the 2D-FWHT layer runs about 24 times as fast as the regular $3\times 3$ convolution with 19.51\% less RAM usage in an NVIDIA Jetson Nano experiment.