 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLISS: Robust Sequence-to-Sequence Learning via Self-Supervised Input Representation
Paper and Code



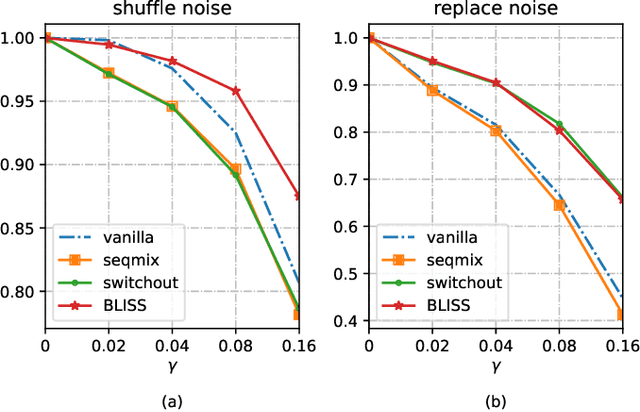
Data augmentations (DA) are the cores to achieving robust sequence-to-sequence learning on various natural language processing (NLP) tasks. However, most of the DA approaches force the decoder to make predictions conditioned on the perturbed input representation, underutilizing supervised information provided by perturbed input. In this work, we propose a framework-level robust sequence-to-sequence learning approach, named BLISS, via self-supervised input representation, which has the great potential to complement the data-level augmentation approaches. The key idea is to supervise the sequence-to-sequence framework with both the \textit{supervised} ("input$\rightarrow$output") and \textit{self-supervised} ("perturbed input$\rightarrow$input") information. We conduct comprehensive experiments to validate the effectiveness of BLISS on various tasks, including machine translation, grammatical error correction, and text summarization. The results show that BLISS outperforms significantly the vanilla Transformer and consistently works well across tasks than the other five contrastive baselines. Extensive analyses reveal that BLISS learns robust representations and rich linguistic knowledge, confirming our claim. Source code will be released upon publication.